Seções do site
Escolha dos editores:
- O melhor programa de reconhecimento de fala russo Reconhecimento de fala offline como desativar
- Como descobrir o VID, PID de um pendrive e para que servem esses números de identificação?
- Huawei P8Lite - Especificações
- Como desbloquear um telefone Xiaomi se você esqueceu sua senha
- Apptools: como ganhar dinheiro jogando
- Lenovo Vibe K5 Plus - Especificações Especificações de áudio e câmera
- Decidiu mudar do Windows para o Mac?
- Como usar o Google Fotos, visão geral das funções de login do Google Fotos
- Sistema de pagamento Payza (ex-Alertpay) Payza faça login em sua conta pessoal
- Como abrir o APK e como editar?
Anúncio
| Reconhecimento de fala ultrarrápido sem servidores usando um exemplo real. O melhor programa de reconhecimento de fala russo Reconhecimento de fala offline como desativar |
|
Atualizado: segunda-feira, 31 de julho de 2017 O que a ideia semifantástica de falar com um computador tem a ver com a fotografia profissional? Quase nenhum, a menos que você seja fã da ideia de desenvolvimento infinito de todo o ambiente técnico do homem. Imagine por um momento que você está dando ordens de voz à sua câmera para alterar a distância focal e fazer uma correção de exposição de mais meio ponto. O controle remoto da câmera já foi implementado, mas aí você precisa apertar os botões silenciosamente, mas aqui está uma câmera auditiva! Tornou-se tradição citar algum filme de ficção científica como exemplo de comunicação de voz entre uma pessoa e um computador, por exemplo “2001: Uma Odisseia no Espaço” dirigido por Stanley Kubrick. Lá, o computador de bordo não apenas conduz um diálogo significativo com os astronautas, mas também pode ler os lábios como uma pessoa surda. Em outras palavras, a máquina aprendeu a reconhecer a fala humana sem erros. Talvez o controle remoto de voz da câmera pareça supérfluo para alguns, mas muitos gostariam desta frase "Leve-nos para baixo, querido" e a foto de toda a família contra o fundo de uma palmeira está pronta. Bom, então prestei homenagem à tradição e sonhei um pouco. Mas, falando de coração, este artigo foi difícil de escrever, e tudo começou com um presente na forma de um smartphone com sistema operacional Android 4. Este modelo HUAWEI U8815 possui uma pequena tela sensível ao toque de quatro polegadas e um teclado na tela. É um pouco incomum digitar, mas acontece que não é particularmente necessário. (imagem01) 1. Reconhecimento de voz em um smartphone com sistema operacional AndroidAo experimentar um novo brinquedo, notei o gráfico de um microfone na barra de pesquisa Google e no teclado no Notes. Anteriormente, eu não estava interessado no significado desse símbolo. Eu tive conversas em Skype e digitou letras no teclado. Isso é o que a maioria dos usuários da Internet faz. Mas como me explicaram mais tarde, no mecanismo de busca Google foi adicionada pesquisa por voz em russo e apareceram programas que permitem ditar mensagens curtas ao usar um navegador "Cromada".
Não foi uma descoberta para mim que os avanços modernos no campo do controle de voz possibilitam dar comandos a eletrodomésticos, carros e robôs. O modo de comando foi introduzido em versões anteriores do Windows, OS/2 e Mac OS. Já me deparei com programas falantes, mas para que servem? Talvez seja minha peculiaridade que seja mais fácil para mim falar do que digitar no teclado, mas no celular não consigo digitar nada. Você tem que anotar os contatos em um laptop com teclado normal e transferi-los via cabo USB. Mas simplesmente falar ao microfone e fazer com que o computador digitasse o texto sem erros era um sonho para mim. A atmosfera de desesperança foi mantida pelas discussões nos fóruns. Em todos os lugares havia um pensamento tão triste:
Ao mesmo tempo, análises de programas de entrada de texto por voz em inglês indicaram claros sucessos. Por exemplo, IBM ViaVoice 98 Edição Executiva tinha um vocabulário básico de 64.000 palavras e a capacidade de adicionar o mesmo número de suas próprias palavras. A porcentagem de reconhecimento de palavras sem treinar o programa foi de cerca de 80% e durante o trabalho subsequente com um usuário específico atingiu 95%. Entre os programas de reconhecimento da língua russa, vale destacar “Gorynych” - um acréscimo ao Dragon Dictate 2.5 em inglês. Contarei a vocês sobre a busca e depois a “batalha com os cinco Gorynychs” na segunda parte da revisão. O primeiro que encontrei foi o "Dragão Inglês". 3. Programa de reconhecimento de fala contínuo “Dragon Naturally Speaking”Versão moderna do programa da empresa "Nuance" acabei com um velho amigo meu do Instituto de Línguas Estrangeiras de Minsk. Ela o trouxe de uma viagem ao exterior e comprou pensando que poderia ser uma “secretária de informática”. Mas algo não deu certo e o programa ficou no laptop, quase esquecido. Devido à falta de uma experiência clara, tive que ir pessoalmente até meu amigo. Toda esta longa introdução é necessária para uma correta compreensão das conclusões que tirei. O nome completo do meu primeiro dragão foi: . O programa está em inglês e tudo nele fica claro mesmo sem manual. O primeiro passo é criar um perfil de um usuário específico para determinar as características sonoras das palavras em sua performance. Foi isso que eu fiz - a idade, o país e as características de pronúncia do falante são importantes. Minha escolha é a seguinte: idade entre 22 e 54 anos, inglês do Reino Unido, pronúncia padrão. A seguir estão várias janelas onde você configura seu microfone. (imagem04)
A essência desta etapa de trabalho com o programa é extremamente simples - o texto é exibido na janela, com uma seta amarela acima dele. Quando pronunciada corretamente, a seta se move pelas frases e na parte inferior há uma barra de progresso do treino. Eu tinha praticamente esquecido meu inglês de conversação, então progredi com dificuldade. O tempo também era limitado - o computador não era meu e tive que interromper o treino. Mas uma amiga disse que fez o teste em menos de meia hora. (imagem05)
Mas foi importante para mim como esse “dragão” escreve em russo. Como você entendeu na descrição anterior, ao treinar o programa, você só pode selecionar texto em inglês, simplesmente não há russo; É claro que não será possível treinar o reconhecimento da fala russa. Na próxima foto você pode ver qual frase o programa digitou ao pronunciar a palavra russa “Olá”. (imagem06)
Mas também há experiência útil. Uma amiga minha pediu para ver o estado de seu laptop. De alguma forma, lentamente ele começou a trabalhar. Isto não é surpreendente - a partição do sistema tinha apenas 5% de espaço livre. Ao excluir programas desnecessários, vi que a versão oficial ocupava mais de 2,3 GB. Esta figura será útil para nós mais tarde. (imagem.07) Reconhecer a língua russa, no fim das contas, não foi uma tarefa trivial. Em Minsk consegui encontrar “Gorynych” de um amigo. Ele procurou por muito tempo o disco em seus antigos escombros e, segundo ele, esta é a publicação oficial. O programa foi instalado instantaneamente e descobri que seu dicionário contém 5.000 palavras em russo mais 100 comandos e 600 palavras em inglês mais 31 comandos. Primeiro você precisa configurar o microfone, o que eu fiz. Então abri o dicionário e adicionei a palavra "exame" porque não estava no dicionário do programa. Tentei falar de forma clara e monótona. Por fim, abri o programa Gorynych Pro 3.0, ativei o modo de ditado e recebi esta lista de “palavras com som próximo”. (imagem.09)
5. Recursos de voz do GooglePara trabalhar com voz em um computador Windows normal, você precisará instalar um navegador Google Chrome. Se estiver usando online, você pode clicar no link da loja de software no canto inferior direito. Lá, totalmente gratuito, encontrei dois programas e duas extensões para entrada de texto por voz. Os programas são chamados "Bloco de notas de voz" E "Voicenot - voz para texto". Após a instalação, eles podem ser encontrados na aba "Formulários" seu navegador "Cromo". (imagem. 10)
6. Resultados do trabalho com programas de reconhecimento de fala russoUm pouco de experiência na utilização de programas de entrada de texto por voz mostrou excelente implementação deste recurso nos servidores de uma empresa de Internet Google. Sem qualquer treinamento prévio, as palavras são reconhecidas corretamente. Isto indica que o problema do reconhecimento da fala russa foi resolvido. Agora podemos dizer que o resultado da evolução Google será um novo critério para avaliação de produtos de outros fabricantes. Gostaria que o sistema de reconhecimento funcionasse offline, sem acesso aos servidores da empresa - é mais prático e rápido. Mas não se sabe quando um programa independente para trabalhar com um fluxo contínuo de fala russa será lançado. Vale a pena supor, porém, que com a oportunidade de treinar, essa “criação” se tornará um verdadeiro avanço. Programas de desenvolvedores russos "Gorynych", "Dictógrafo" E "Combate" Entrarei em detalhes na segunda parte desta revisão. Este artigo foi escrito muito lentamente porque a busca pelos discos originais agora é difícil. No momento, já tenho todas as versões dos mecanismos russos de reconhecimento de voz para texto, exceto “Combat 2.52”. Nenhum dos meus amigos ou colegas tem este programa e eu mesmo tenho apenas algumas críticas elogiosas nos fóruns. É verdade que havia uma opção tão estranha - baixar “Combat” via SMS, mas não gosto disso. (imagem16)
Este telefone tem reconhecimento de fala ou entrada de voz, mas só funciona via Internet, conectando-se aos serviços do Google. Mas um telefone pode ser ensinado a reconhecer a fala sem a Internet. Veremos como habilitar o reconhecimento do idioma russo em desligada. Para que este método funcione, você deve ter dois aplicativos instalados Pesquisa por voz E Pesquisa do Google, embora esses programas já estejam presentes no firmware de fábrica. Para firmwareVá para as configurações do seu telefone e selecione Selecione o idioma russo e faça o download. Para firmware 2.8BNo novo firmware, o item de menu " Reconhecimento de fala off-line" ausente. Se você tinha pacotes offline instalados antes da atualização do firmware e não limpou (redefiniu as configurações) durante a atualização, eles deveriam ter sido preservados. Caso contrário, você terá que reverter para o firmware 2.2 , instale pacotes de voz e só então atualize o sistema para 2,8B. Para dispositivos Rev.BInstalamos a atualização por meio de recuperação e aproveitamos o reconhecimento de voz no oyline. 2. Baixe o banco de dados da fala russa e copie-o para o cartão SD Baixe Russo_offline.zip 1301 3. Entre na recuperação segurando (Volume + e Ligado) com o telefone desligado. 4. Selecione Aplicar atualização do armazenamento externo e selecione o arquivo baixado. ) usando um exemplo real do Hello World de controle de eletrodomésticos. Por que de repente?Tendo descoberto isso recentemente, perguntei ao autor por que ele queria usar o reconhecimento de fala baseado em servidor para seu programa (na minha opinião, isso era desnecessário e causava alguns problemas). Para tanto, poderia descrever com mais detalhes o uso de métodos alternativos para projetos onde não há necessidade de reconhecer nada e o dicionário consiste em um conjunto finito de palavras. E mesmo com um exemplo de aplicação prática...Por que precisamos de mais alguma coisa além do Yandex e do Google?Para essa “aplicação prática” escolhi o tema controle de voz para casa inteligente.Por que exatamente este exemplo? Porque mostra diversas vantagens do reconhecimento de fala totalmente local em relação ao reconhecimento usando soluções em nuvem. Nomeadamente:
Observação Deixe-me fazer uma reserva desde já que essas vantagens podem ser consideradas vantagens apenas para uma determinada classe de projetos, Onde estamos sabemos com certeza com antecedência, com qual dicionário e com qual gramática o usuário irá operar. Ou seja, quando não precisamos reconhecer texto arbitrário (por exemplo, uma mensagem SMS ou uma consulta de pesquisa). Caso contrário, o reconhecimento na nuvem é indispensável. Assim, o Android pode reconhecer a fala sem a Internet!Sim, sim... Somente no JellyBean. E só a partir de meio metro, não mais. E esse reconhecimento é o mesmo ditado, só que usando um modelo muito menor. Portanto, também não podemos gerenciá-lo ou configurá-lo. E o que ela retornará para nós na próxima vez é desconhecido. Embora seja ideal para SMS!O que nós fazemos?Implementaremos um controle remoto de voz para eletrodomésticos, que funcionará com precisão e rapidez, a partir de alguns metros e até mesmo em smartphones, tablets e relógios Android baratos, de baixa qualidade e muito baratos. Aplicações práticas são abundantes De manhã, sem abrir os olhos, você bateu a palma da mão na tela do smartphone na mesa de cabeceira e comandou “Bom dia!” - começa o roteiro, a cafeteira liga e zumbe, ouve-se uma música agradável, as cortinas se abrem. Transcrições A gramática descreve o que o que o usuário pode dizer. Para o Pocketsphinx saber, Como ele irá pronunciá-la, é necessário que cada palavra da gramática escreva como soa no modelo de linguagem correspondente. Aquilo é transcrição toda palavra. É chamado dicionário. As transcrições são descritas usando uma sintaxe especial. Por exemplo: Em princípio, nada complicado. Uma vogal dupla na transcrição indica acento. Uma consoante dupla é uma consoante suave seguida por uma vogal. Todas as combinações possíveis para todos os sons da língua russa. É claro que não podemos descrever antecipadamente todas as transcrições em nossa aplicação, pois não sabemos antecipadamente os nomes que o usuário dará aos seus dispositivos. Portanto, geraremos tais transcrições “on the fly” de acordo com algumas regras da fonética russa. Para fazer isso, você pode implementar a seguinte classe PhonMapper, que pode receber uma string como entrada e gerar a transcrição correta para ela. Ativação por vozEsta é a capacidade do mecanismo de reconhecimento de fala de “ouvir a transmissão” o tempo todo para reagir a uma frase (ou frases) predeterminada. Ao mesmo tempo, todos os outros sons e fala serão descartados. Isto não é o mesmo que descrever a gramática e apenas ligar o microfone. Não apresentarei aqui a teoria desta tarefa e a mecânica de seu funcionamento. Deixe-me apenas dizer que recentemente os programadores que trabalham no Pocketsphinx implementaram essa função e agora ela está disponível imediatamente na API.Uma coisa definitivamente vale a pena mencionar. Para uma frase de ativação, você precisa não apenas especificar a transcrição, mas também selecionar a apropriada valor limite de sensibilidade. Um valor muito pequeno levará a muitos falsos positivos (isto é, quando você não disse a frase de ativação, mas o sistema a reconhece). E muito alto - para imunidade. Portanto, esta configuração é de particular importância. Faixa aproximada de valores - de 1e-1 a 1e-40 dependendo da frase de ativação. Ativação do sensor de proximidade Esta tarefa é específica do nosso projeto e não está diretamente relacionada ao reconhecimento. O código pode ser visto diretamente na atividade principal. Vamos começar o reconhecimentoPocketsphinx fornece uma API conveniente para configurar e executar o processo de reconhecimento. Estas são as aulas SpechRecognizer E Configuração do SpeechRecognizer.Esta é a aparência da configuração e do lançamento do reconhecimento: PhonMapper phonMapper = new PhonMapper(getAssets().open("dict/ru/hotwords")); Gramática gramatical = nova gramática(nomes, phonMapper); gramática.addWords(hotword); Arquivos de Dados dataFiles = new DataFiles(getPackageName(), "ru"); Arquivo hmmDir = new Arquivo(dataFiles.getHmm()); Arquivo dict = new Arquivo(dataFiles.getDict()); Arquivo jsgf = novo arquivo(dataFiles.getJsgf()); copyAssets(hmmDir); saveFile(jsgf, gramática.getJsgf()); saveFile(dict, gramática.getDict()); mRecognizer = SpeechRecognizerSetup.defaultSetup() .setAcousticModel(hmmDir) .setDictionary(dict) .setBoolean("-remove_noise", false) .setKeywordThreshold(1e-7f) .getRecognizer(); mRecognizer.addKeyphraseSearch(KWS_SEARCH, palavra-chave); mRecognizer.addGrammarSearch(COMMAND_SEARCH, jsgf); Aqui, primeiro copiamos todos os arquivos necessários para o disco (o Pocketpshinx requer que um modelo acústico, gramática e dicionário com transcrições estejam no disco). Em seguida, o próprio mecanismo de reconhecimento é configurado. São indicados os caminhos para os arquivos do modelo e do dicionário, bem como alguns parâmetros (limiar de sensibilidade para a frase de ativação). A seguir, é configurado o caminho para o arquivo com a gramática, bem como a frase de ativação. Como você pode ver neste código, um mecanismo está configurado para reconhecimento gramatical e de frase de ativação. Por que isso é feito? Para que possamos alternar rapidamente entre o que precisamos reconhecer atualmente. Esta é a aparência do início do processo de reconhecimento da frase de ativação: MRecognizer.startListening(KWS_SEARCH); MRecognizer.startListening(COMMAND_SEARCH, 3000); Como obter o resultado do reconhecimentoPara obter o resultado do reconhecimento, você também deve especificar um ouvinte de evento que implemente a interface ReconhecimentoListener.Possui vários métodos que são chamados pelo pocketsphinx quando ocorre um dos eventos:
Ao implementar os métodos onPartialResult e onResult de uma forma ou de outra, você pode alterar a lógica de reconhecimento e obter o resultado final. Veja como isso é feito no caso de nossa aplicação: @Override public void onEndOfSpeech() ( Log.d(TAG, "onEndOfSpeech"); if (mRecognizer.getSearchName().equals(COMMAND_SEARCH)) ( mRecognizer.stop(); ) ) @Override public void onPartialResult(hipótese da hipótese) ( if (hipótese == nulo) return; String text = hipotese.getHypstr(); if (KWS_SEARCH.equals(mRecognizer.getSearchName())) ( startRecognition(); ) else ( Log.d(TAG, text); ) ) @Override public void onResult (hipótese de hipótese) ( mMicView.setBackgroundResource (R.drawable.background_big_mic); mHandler.removeCallbacks (mStopRecognitionCallback); String text = hipótese! , "onResult " + texto); if (COMMAND_SEARCH.equals(mRecognizer.getSearchName())) ( if (text != null) ( Toast.makeText(this, text, Toast.LENGTH_SHORT).show(); process(texto );mRecognizer.startListening(KWS_SEARCH); Quando recebemos o evento onEndOfSpeech, e se ao mesmo tempo reconhecemos o comando a ser executado, precisamos interromper o reconhecimento, após o qual onResult será chamado imediatamente. Privado sincronizado void startRecognition() ( if (mRecognizer == null || COMMAND_SEARCH.equals(mRecognizer.getSearchName())) return; mRecognizer.cancel(); new ToneGenerator(AudioManager.STREAM_MUSIC, ToneGenerator.MAX_VOLUME).startTone(ToneGenerator. TONE_CDMA_PIP, 200); post(400, new Runnable() ( @Override public void run() ( mMicView.setBackgroundResource(R.drawable.background_big_mic_green); mRecognizer.startListening(COMMAND_SEARCH, 3000); Log.d(TAG, "Ouvir comandos"); post(4000, mStopRecognitionCallback); ) )); ) Como transformar string reconhecida em comandosBem, tudo aqui é específico para uma aplicação específica. No caso do exemplo simples, simplesmente retiramos os nomes dos dispositivos da linha, procuramos o dispositivo desejado e alteramos seu estado usando uma solicitação HTTP para o controlador de casa inteligente ou relatamos seu estado atual (como no caso de um termostato). Essa lógica pode ser vista na classe Controller.Como sintetizar a falaA síntese de fala é a operação inversa do reconhecimento. Aqui é o contrário: você precisa transformar uma linha de texto em fala para que o usuário possa ouvi-la.No caso do termostato, temos que fazer com que nosso dispositivo Android diga a temperatura atual. Usando a API Texto para fala isso é muito fácil de fazer (graças ao Google pelo maravilhoso TTS feminino para o idioma russo): Privado void speak(String texto) (sincronizado (mSpeechQueue) ( mRecognizer.stop(); mSpeechQueue.add(texto); HashMap Provavelmente direi algo banal, mas antes do processo de síntese, é necessário desabilitar o reconhecimento. Em alguns dispositivos (por exemplo, todos os dispositivos Samsung) geralmente é impossível ouvir o microfone e sintetizar algo ao mesmo tempo. Final privado TextToSpeech.OnUtteranceCompletedListener mUtteranceCompletedListener = new TextToSpeech.OnUtteranceCompletedListener() ( @Override public void onUtteranceCompleted(String expressãoId) ( sincronizado (mSpeechQueue) ( mSpeechQueue.poll(); if (mSpeechQueue.isEmpty()) ( mRecognizer.startListening ( KWS_PESQUISA) ) ) ) ); Nele, simplesmente verificamos se há mais alguma coisa na fila de síntese e habilitamos o reconhecimento da frase de ativação se não houver mais nada. E é tudo?Sim! Como você pode ver, reconhecer a fala de forma rápida e eficiente diretamente no dispositivo não é nada difícil, graças à presença de projetos maravilhosos como o Pocketsphinx. Ele fornece uma API muito conveniente que pode ser usada para resolver problemas relacionados ao reconhecimento de comandos de voz.Neste exemplo, atribuímos reconhecimento a uma tarefa completamente específica - controle de voz de dispositivos domésticos inteligentes. Devido ao reconhecimento local, alcançamos velocidade muito alta e minimizamos erros. Nenhum programa pode substituir completamente o trabalho manual de transcrição de fala gravada. Porém, existem soluções que podem agilizar e facilitar significativamente a tradução da fala em texto, ou seja, simplificar a transcrição. Transcrição é a gravação de um arquivo de áudio ou vídeo em formato de texto. Existem tarefas pagas na Internet, quando o intérprete recebe uma determinada quantia em dinheiro pela transcrição do texto. A tradução de fala em texto é útil
Descreveremos as ferramentas mais eficazes disponíveis em PCs, aplicativos móveis e serviços online. 1 Site Speechpad.ruEste é um serviço online que permite traduzir fala em texto usando o navegador Google Chrome. O serviço funciona com microfone e arquivos prontos. Claro, a qualidade será muito maior se você usar um microfone externo e ditar você mesmo. Porém, o serviço faz um bom trabalho mesmo com vídeos do YouTube. Clique em “Ativar gravação”, responda à pergunta sobre “Usar microfone” - para isso, clique em “Permitir”. As longas instruções sobre a utilização do serviço podem ser recolhidas clicando no botão 1 da Fig. 3. Você pode se livrar da publicidade fazendo um simples cadastro.
Arroz. 3. Serviço de teclado de fala O resultado final é fácil de editar. Para fazer isso, você precisa corrigir manualmente a palavra destacada ou ditá-la novamente. Os resultados do trabalho ficam salvos na sua conta pessoal, também podem ser baixados para o seu computador. Lista de videoaulas sobre como trabalhar com o Speechpad: Você pode transcrever vídeos do Youtube ou do seu computador, porém, será necessário um mixer, mais detalhes: Vídeo "transcrição de áudio"
O serviço funciona em sete idiomas. Há um pequeno sinal de menos. Está no fato de que se for necessário transcrever um arquivo de áudio finalizado, seu som será ouvido pelos alto-falantes, o que cria interferência adicional na forma de eco. 2 Ditado de serviço.ioUm maravilhoso serviço online que permite traduzir fala em texto de forma fácil e gratuita.
Arroz. 4. Ditado de serviço.io 1 na Fig. 4 – O idioma russo pode ser selecionado no final da página. No navegador Google Chrome, o idioma está selecionado, mas por algum motivo no Mozilla não existe essa opção. Vale ressaltar que foi implementada a capacidade de salvar automaticamente o resultado final. Isso evitará a exclusão acidental como resultado do fechamento de uma guia ou navegador. Este serviço não reconhece arquivos finalizados. Funciona com microfone. Você precisa nomear sinais de pontuação ao ditar. O texto é reconhecido corretamente, não há erros ortográficos. Você mesmo pode inserir sinais de pontuação no teclado. O resultado final pode ser salvo no seu computador. 3 RealSpeakerEste programa permite traduzir facilmente a fala humana em texto. Ele foi projetado para funcionar em diferentes sistemas: Windows, Android, Linux, Mac. Com sua ajuda, você pode converter a fala ouvida em um microfone (por exemplo, pode ser embutida em um laptop), bem como gravada em arquivos de áudio. Pode compreender 13 línguas mundiais. Existe uma versão beta do programa que funciona como um serviço online: Você precisa seguir o link acima, selecionar o idioma russo, enviar seu arquivo de áudio ou vídeo para o serviço online e pagar pela transcrição. Após a transcrição, você pode copiar o texto resultante. Quanto maior o arquivo para transcrição, mais tempo levará para processá-lo, mais detalhes:
Em 2017 existia a opção de transcrição gratuita usando RealSpeaker, mas em 2018 não existe essa opção. É muito confuso que o arquivo transcrito esteja disponível para download para todos os usuários; talvez isso seja melhorado; Os contatos do desenvolvedor (VKontakte, Facebook, Youtube, Twitter, e-mail, telefone) do programa podem ser encontrados na página de seu site (mais precisamente, no rodapé do site): 4 Registrador de falaUma alternativa ao aplicativo anterior para dispositivos móveis rodando em Android. Disponível gratuitamente na loja de aplicativos: O texto é editado automaticamente e sinais de pontuação são adicionados. Muito conveniente para ditar notas para você mesmo ou fazer listas. Como resultado, o texto terá uma qualidade muito decente. 5 Ditado do DragãoEste é um aplicativo distribuído gratuitamente para dispositivos móveis da Apple. O programa pode funcionar com 15 idiomas. Permite editar o resultado e selecionar as palavras desejadas na lista. Você precisa pronunciar todos os sons com clareza, não fazer pausas desnecessárias e evitar a entonação. Às vezes há erros nas terminações das palavras. O aplicativo Dragon Dictation é usado pelos proprietários, por exemplo, para ditar uma lista de compras em uma loja enquanto se deslocam pelo apartamento. Quando chego lá, posso olhar o texto da nota e não preciso ouvir.
Também serviços úteis: Receba os artigos mais recentes sobre conhecimentos de informática diretamente em sua caixa de entrada. |
 Eu disse uma frase de três palavras, o programa as identificou e as mostrou em uma célula com fundo azul. Havia algo para se surpreender aqui, porque todas as palavras foram escritas corretamente. Se você clicar nesta célula, a frase aparecerá no campo de texto do bloco de notas do Android. Então falei mais algumas frases e enviei uma mensagem para a assistente via SMS.
Eu disse uma frase de três palavras, o programa as identificou e as mostrou em uma célula com fundo azul. Havia algo para se surpreender aqui, porque todas as palavras foram escritas corretamente. Se você clicar nesta célula, a frase aparecerá no campo de texto do bloco de notas do Android. Então falei mais algumas frases e enviei uma mensagem para a assistente via SMS. 2. Uma breve história dos programas de reconhecimento de voz.
2. Uma breve história dos programas de reconhecimento de voz. A próxima etapa para programas sérios de reconhecimento de fala é o treinamento nas características de pronúncia de uma pessoa específica. Você deve escolher a natureza do texto: minha escolha é uma breve instrução de ditado, mas você também pode “encomendar” uma história humorística.
A próxima etapa para programas sérios de reconhecimento de fala é o treinamento nas características de pronúncia de uma pessoa específica. Você deve escolher a natureza do texto: minha escolha é uma breve instrução de ditado, mas você também pode “encomendar” uma história humorística. Recusando-me a deixar o programa adaptar minha pronúncia, fui para a janela principal e iniciei o editor de texto integrado. Ele falou palavras individuais de alguns textos que encontrou no computador. O programa imprimiu as palavras que ele disse corretamente e substituiu as que ele disse mal por algo “inglês”. Tendo pronunciado claramente o comando “apagar linha” em inglês, o programa o executou. Isso significa que li os comandos corretamente e o programa os reconhece sem treinamento prévio.
Recusando-me a deixar o programa adaptar minha pronúncia, fui para a janela principal e iniciei o editor de texto integrado. Ele falou palavras individuais de alguns textos que encontrou no computador. O programa imprimiu as palavras que ele disse corretamente e substituiu as que ele disse mal por algo “inglês”. Tendo pronunciado claramente o comando “apagar linha” em inglês, o programa o executou. Isso significa que li os comandos corretamente e o programa os reconhece sem treinamento prévio. O resultado da conversa com o primeiro dragão acabou sendo um tanto cômico. Se você ler atentamente o texto do site oficial, poderá ver a “especialização” em inglês deste produto de software. Além disso, ao carregar, lemos “Inglês” na janela do programa. Então, por que tudo isso foi necessário? É claro que os fóruns e os rumores são os culpados...
O resultado da conversa com o primeiro dragão acabou sendo um tanto cômico. Se você ler atentamente o texto do site oficial, poderá ver a “especialização” em inglês deste produto de software. Além disso, ao carregar, lemos “Inglês” na janela do programa. Então, por que tudo isso foi necessário? É claro que os fóruns e os rumores são os culpados...

 O resultado me intrigou, porque claramente diferia para pior do trabalho de um smartphone Android, e decidi tentar outros programas de “ Loja on-line do Google Chrome". E deixei lidar com as “cobras gorynych” para mais tarde. Eu pensei que era adiamento ação no espírito original russo
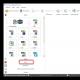
O resultado me intrigou, porque claramente diferia para pior do trabalho de um smartphone Android, e decidi tentar outros programas de “ Loja on-line do Google Chrome". E deixei lidar com as “cobras gorynych” para mais tarde. Eu pensei que era adiamento ação no espírito original russo As extensões são chamadas "Hotword da Pesquisa por voz do Google (Beta) 0.1.0.5" E "Entrada de texto por voz - Speechpad.ru 5.4". Após a instalação, eles podem ser desligados ou excluídos na guia "Extensões".(imagem. 11)
As extensões são chamadas "Hotword da Pesquisa por voz do Google (Beta) 0.1.0.5" E "Entrada de texto por voz - Speechpad.ru 5.4". Após a instalação, eles podem ser desligados ou excluídos na guia "Extensões".(imagem. 11) Nota de voz. Na guia do aplicativo no navegador Chrome, clique duas vezes no ícone do programa. Uma caixa de diálogo será aberta como na imagem abaixo. Ao clicar no ícone do microfone, você fala frases curtas no microfone. O programa transmite suas palavras para o servidor de reconhecimento de fala e digita o texto na janela. Todas as palavras e frases mostradas na ilustração foram digitadas na primeira vez. Obviamente, este método só funciona quando há uma conexão ativa com a Internet. (imagem. 12)
Nota de voz. Na guia do aplicativo no navegador Chrome, clique duas vezes no ícone do programa. Uma caixa de diálogo será aberta como na imagem abaixo. Ao clicar no ícone do microfone, você fala frases curtas no microfone. O programa transmite suas palavras para o servidor de reconhecimento de fala e digita o texto na janela. Todas as palavras e frases mostradas na ilustração foram digitadas na primeira vez. Obviamente, este método só funciona quando há uma conexão ativa com a Internet. (imagem. 12) Bloco de notas de voz. Se você iniciar o programa na guia de aplicativos, uma nova guia da página da Internet será aberta Speechpad.ru. Existem instruções detalhadas sobre como usar este serviço e um formulário compacto. Este último é mostrado na ilustração abaixo. (imagem. 13)
Bloco de notas de voz. Se você iniciar o programa na guia de aplicativos, uma nova guia da página da Internet será aberta Speechpad.ru. Existem instruções detalhadas sobre como usar este serviço e um formulário compacto. Este último é mostrado na ilustração abaixo. (imagem. 13) Entrada de voz Texto permite que você preencha campos de texto em páginas da Internet usando sua voz. Por exemplo, fui para minha página "Google+". No campo de entrada da nova mensagem, clique com o botão direito e selecione "SpeechPad". A janela de entrada rosa indica que você pode ditar seu texto. (imagem. 14)
Entrada de voz Texto permite que você preencha campos de texto em páginas da Internet usando sua voz. Por exemplo, fui para minha página "Google+". No campo de entrada da nova mensagem, clique com o botão direito e selecione "SpeechPad". A janela de entrada rosa indica que você pode ditar seu texto. (imagem. 14) Pesquisa por voz do Google permite que você pesquise por voz. Quando você instala e ativa esta extensão, um símbolo de microfone aparece na barra de pesquisa. Ao pressioná-lo, um símbolo aparecerá em um grande círculo vermelho. Basta dizer sua frase de pesquisa e ela aparecerá nos resultados da pesquisa. (imagem. 15)
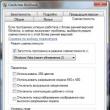
Pesquisa por voz do Google permite que você pesquise por voz. Quando você instala e ativa esta extensão, um símbolo de microfone aparece na barra de pesquisa. Ao pressioná-lo, um símbolo aparecerá em um grande círculo vermelho. Basta dizer sua frase de pesquisa e ela aparecerá nos resultados da pesquisa. (imagem. 15) Observação importante: para que o microfone funcione com extensões do Chrome, você precisa permitir o acesso ao microfone nas configurações do seu navegador. Ele está desabilitado por padrão por motivos de segurança. Vá para Configurações→Informações pessoais→Configurações de conteúdo. (Para acessar todas as configurações no final da lista, clique em Mostrar configurações avançadas). Uma caixa de diálogo será aberta Configurações de conteúdo da página. Selecione um item na lista Multimídia→microfone.
Observação importante: para que o microfone funcione com extensões do Chrome, você precisa permitir o acesso ao microfone nas configurações do seu navegador. Ele está desabilitado por padrão por motivos de segurança. Vá para Configurações→Informações pessoais→Configurações de conteúdo. (Para acessar todas as configurações no final da lista, clique em Mostrar configurações avançadas). Uma caixa de diálogo será aberta Configurações de conteúdo da página. Selecione um item na lista Multimídia→microfone.


| Ler: |
|---|
Popular:
Novo
- Como descobrir o VID, PID de um pendrive e para que servem esses números de identificação?
- Huawei P8Lite - Especificações
- Como desbloquear um telefone Xiaomi se você esqueceu sua senha
- Apptools: como ganhar dinheiro jogando
- Lenovo Vibe K5 Plus - Especificações Especificações de áudio e câmera
- Decidiu mudar do Windows para o Mac?
- Como usar o Google Fotos, visão geral das funções de login do Google Fotos
- Sistema de pagamento Payza (ex-Alertpay) Payza faça login em sua conta pessoal
- Como abrir o APK e como editar?
- Análise do smartphone Alpha GT da Highscreen Embalagem e entrega