Seções do site
Escolha dos editores:
- Produzindo parte de um sprite de imagem HTML
- Configurando detalhes adicionais e informações adicionais para detalhes adicionais da nomenclatura 1C e diferenças de informações
- O que fazer quando não há dados cadastrais
- Solicitação de seleção de dados (fórmulas) em MS EXCEL Seleção Excel por macro de condição
- E-mail temporário temporário E-mail temporário, sites de e-mail, registro de mídia social
- O que fazer se o computador não vir o telefone através da porta USB
- Como instalar o Windows no Mac?
- Firmware de configuração do Asus rt n16
- Como descobrir o número de bits do sistema operacional e do processador no Windows
- Como desativar o Firewall do Windows: desativação e desativação completa de programas individuais. Como desativar completamente o firewall do Windows 7
Anúncio
| Selecionando a codificação de texto ao abrir e salvar arquivos. O que fazer se houver hieróglifos em vez de texto (no Word, navegador ou documento de texto) O documento de texto abre com hieróglifos |
|
Foi a primeira vez que vi algo assim - os arquivos e pastas do pen drive desapareceram e, em vez deles, apareceram arquivos com nomes incompreensíveis na forma de “kryakozyabriks”, vamos chamá-los de hieróglifos. A unidade flash foi aberta com padrão usando janelas e além disso, infelizmente, isso não deu resultados positivos.
Todos os arquivos da unidade flash desapareceram, exceto um. Vários arquivos apareceram com nomes estranhos: &, t, n-&, etc. Os arquivos do pen drive desapareceram, mas o Windows mostra que o espaço livre está ocupado. Isso sugere que, embora os arquivos de nosso interesse não sejam exibidos, eles estão localizados na unidade flash.
Embora os arquivos tenham desaparecido, o espaço está ocupado. EM caso específico, 817 MB ocupados O primeiro pensamento sobre a causa do ocorrido é o efeito do vírus. Anteriormente, quando havia um vírus, era utilizado o gerenciador de arquivos FAR Manager, que, via de regra, visualiza todos os arquivos (ocultos e de sistema). Porém, desta vez, o gerente do FAR viu apenas o que o Windows Explorer padrão fazia...
Mesmo o gerente do FAR não conseguiu ver os arquivos “perdidos” Como o Windows não vê arquivos ausentes, ele não tenta alterar os atributos do arquivo usando linha de comando e os comandos atribuem -S -H /S /D.
Nesta situação, como experiência, decidi usar o sistema operacional em Baseado em Linux. Neste caso específico, foi utilizado um disco com sistema operacional Sistema Ubuntu 10.04.3 (mais sobre o Ubuntu e onde baixá-lo). Importante! Não há necessidade de instalar o Ubuntu no seu computador - basta inicializar a partir de um CD, assim como você faz com o . Após inicializar o Ubuntu, a área de trabalho aparecerá e você poderá trabalhar com pastas e arquivos exatamente da mesma forma que no Windows.
Como esperado, o Ubuntu viu mais arquivos comparado ao Windows.
O Ubuntu também exibe os arquivos que não eram visíveis no Windows (clicáveis) A seguir, para não se preocupar com os atributos dos arquivos, foram tomadas medidas básicas: todos os arquivos exibidos foram selecionados e copiados para disco local“D” (claro, você pode copiar arquivos para disco do sistema"C") Agora você pode inicializar o Windows novamente e verificar o que aconteceu.
Agora o Windows vê vários arquivos do Word. Observe que os nomes dos arquivos também são exibidos corretamente Infelizmente, o problema não foi resolvido, pois havia claramente mais arquivos no pen drive (a julgar pelo volume de 817 MB) do que conseguimos extrair. Por esse motivo, vamos tentar verificar se há erros na unidade flash. Solução de problemas de erros da unidade flashPara localizar e corrigir erros em discos, o Windows possui um utilitário padrão. Passo 1. Clique com o botão direito no ícone da unidade flash e selecione o comando “Propriedades”.
Passo 2. Vá até a aba “Serviço” e clique no botão “Executar verificação”.
Passo 3. Clique no botão “Iniciar”.
Depois de verificar e consertar erros do sistema, uma mensagem correspondente aparecerá.
Mensagem: "Alguns erros foram encontrados e corrigidos" Após a eliminação dos erros, os arquivos com hieróglifos desapareceram e apareceram no diretório raiz do pen drive pasta oculta com o nome FOUND.000.
Dentro da pasta FOUND.000 havia 264 arquivos com a extensão CHK. Arquivos com extensão CHK podem armazenar fragmentos de arquivos Vários tipos, extraído de Discos rígidos e unidades flash usando os utilitários ScanDisk ou CHKDISK. Se todos os arquivos do pen drive fossem do mesmo tipo, por exemplo, Documentos do Word com a extensão docx, então em gerenciador de arquivos Comando total selecione todos os arquivos e pressione a combinação de teclas Ctrl + M (Arquivos - Renomeação de grupo). Indicamos qual extensão procurar e como alterá-la.
Neste caso específico, eu só sabia que o pen drive continha documentos Word e arquivos com apresentações em Power Point. Alterar extensões aleatoriamente é muito problemático, por isso é melhor usar programas especializados— eles próprios determinarão que tipo de dados serão armazenados no arquivo. Um desses programas é utilitário gratuito, que não requer instalação em seu computador. Especifique a pasta de origem (coloquei os arquivos CHK em Disco rígido). A seguir, escolhi a opção em que arquivos com extensões diferentes seriam colocados em pastas diferentes.
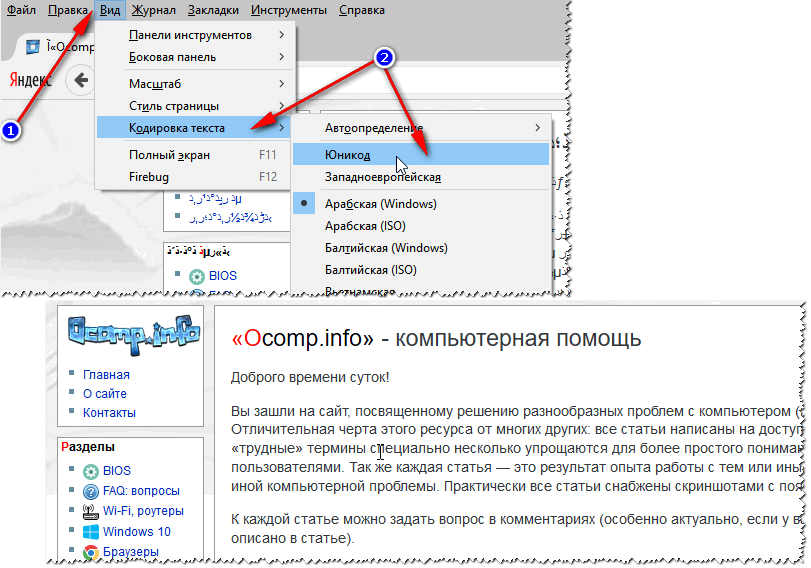
Tudo que você precisa fazer é clicar em “Iniciar” Como resultado do utilitário, três pastas apareceram: O conteúdo de oito arquivos permaneceu não reconhecido. No entanto, a tarefa principal foi concluída, documentos Word e fotografias foram restaurados. A desvantagem é que não foi possível restaurar nomes de arquivos semelhantes, então obviamente você terá que renomear documentos do Word. Quanto aos arquivos com imagens, nomes como FILE0001.jpg, FILE0002.jpg, etc. Pergunta do usuário Olá. Diga-me por que algumas páginas do meu navegador exibem hieróglifos, quadrados e não entendo o que (nada pode ser lido) em vez de texto. Isso não aconteceu antes. Agradeço antecipadamente... Bom dia! Na verdade, às vezes, quando você abre uma página da Internet, em vez de texto, vários “kryakozabry” (como eu os chamo) são mostrados e é impossível lê-los. Isso acontece porque o texto da página está escrito em uma codificação (você pode aprender mais sobre isso em) e o navegador tenta abri-lo em outra. Devido a esta discrepância, em vez de texto existe um conjunto incompreensível de caracteres. Vamos tentar consertar isso... NavegadorNa verdade, antes Internet Explorer muitas vezes distribuíam crackers semelhantes, 👉 (Chrome, navegador Yandex, Opera, Firefox) - eles determinam a codificação muito bem e raramente cometem erros. 👌 Direi ainda mais, em algumas versões do navegador a escolha da codificação já foi removida, e para configurar “manualmente” este parâmetro é necessário baixar add-ons, ou entrar na selva de configurações por 10 ticks.. . E então, suponha que o navegador detectou incorretamente a codificação e você viu o seguinte (como na imagem abaixo 👇).
👉 Já agora! Na maioria das vezes, ocorre confusão entre as codificações UTF (Unicode) e Windows-1251 (a maioria dos sites em russo são feitos nessas codificações).
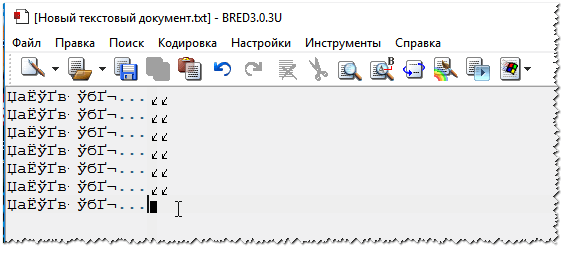
Outra dica: se você não consegue descobrir como alterar a codificação no seu navegador (e geralmente não é realista dar instruções para cada navegador!), recomendo tentar abrir a página em um navegador diferente. Muitas vezes, outro programa abre a página como deveria. Documentos de textoMuitas perguntas sobre crackers são feitas ao abrir alguns documentos de texto. Principalmente os antigos, por exemplo, ao ler o Leiame de algum programa do século passado (digamos, para jogos). É claro que muitos blocos de notas modernos simplesmente não conseguem ler a codificação DOS usada anteriormente. Para resolver esse problema, recomendo usar o editor Bread 3. Criado 3 Um bloco de notas de texto simples e conveniente. Algo insubstituível quando você precisa trabalhar com arquivos de texto antigos. Bred 3 permite que você altere a codificação com um clique e torne o texto ilegível legível! Além de arquivos de texto, ele suporta uma grande variedade de documentos. Em geral, eu recomendo! ✌ Experimente abrir o seu no Bred 3 Documento de texto(com o qual há problemas). Um exemplo é mostrado na minha captura de tela abaixo.
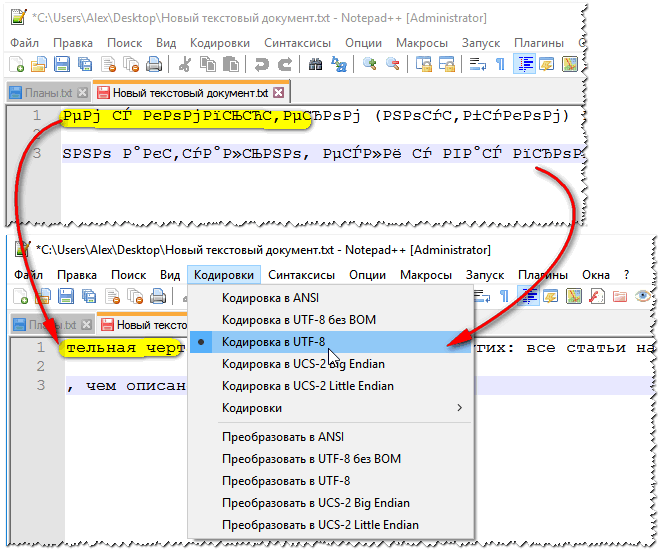
Outro bloco de notas - Notepad++ - também é adequado para trabalhar com arquivos de texto de várias codificações. Em geral, claro, é mais adequado para programação, porque... Suporta várias luzes de fundo para facilitar a leitura do código. Um exemplo de alteração da codificação é mostrado abaixo: para ler o texto, no exemplo abaixo, bastava alterar a codificação ANSI para UTF-8.
Muitas vezes o problema de rachaduras no Word se deve ao fato dos dois formatos se confundirem Doc e Docx. O fato é que desde 2007 o Word (se não me engano) introduziu o formato Documento(permite compactar o documento com mais força do que o Doc e protege-o de forma mais confiável). Portanto, se você possui um Word antigo que não suporta esse formato, ao abrir um documento no Docx, você verá hieróglifos e nada mais. Existem duas soluções: Além disso, quando você abre qualquer documento no Word (cuja codificação ele “duvida”), ele oferece a opção de especificá-lo você mesmo. Um exemplo é mostrado na imagem abaixo, tente selecionar:
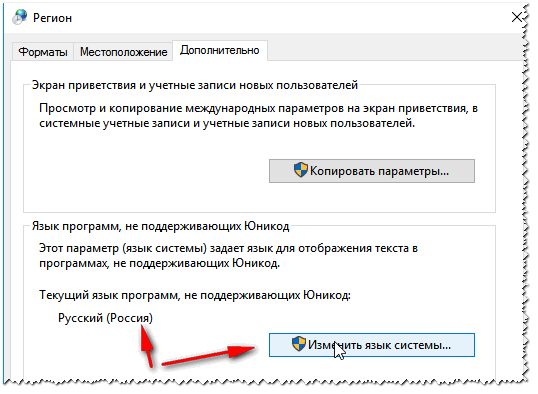
Acontece que alguma janela ou menu de um programa é mostrado com hieróglifos (claro, é impossível ler ou entender algo). Regiões e idiomas no Windows Localização - Rússia E na aba "Adicionalmente" definir o idioma do sistema "Rússia Russa)" . Depois disso, salve as configurações e reinicie o seu PC. Em seguida, verifique novamente se a interface do programa desejado é exibida normalmente.
E, finalmente, isso provavelmente é óbvio para muitos, mas alguns abrem certos arquivos em programas que não foram projetados para isso: por exemplo, em um bloco de notas normal, eles tentam ler um arquivo DOCX ou PDF. Naturalmente, neste caso, em vez de texto, você assistirá aos crackers usarem os programas para os quais são projetados; deste tipo arquivo (WORD 2016+ e Adobe Reader para o exemplo acima). Provavelmente todo usuário de PC encontrou um problema semelhante: você abre uma página ou documento da Internet Microsoft Word- e em vez de texto você vê hieróglifos (vários “kryakozabry”, letras desconhecidas, números, etc. (como na imagem à esquerda...)). É bom que este documento (com hieróglifos) não seja particularmente importante para você, mas e se precisar lê-lo?! Muitas vezes, perguntas semelhantes e pedidos de ajuda para abrir esses textos me são feitos. Neste breve artigo, quero examinar as razões mais populares para o aparecimento de hieróglifos (e, claro, eliminá-los). Hieróglifos em arquivos de texto (.txt) O problema mais popular. O fato é que arquivo de texto(geralmente em formato txt, mas também são formatos: php, css, info, etc.) podem ser salvos em diversas codificações. Uma codificação é um conjunto de caracteres necessários para garantir totalmente que o texto seja escrito em um alfabeto específico (incluindo números e caracteres especiais). Mais detalhes sobre isso aqui: https://ru.wikipedia.org/wiki/Character_set Na maioria das vezes acontece uma coisa: o documento é simplesmente aberto na codificação errada, o que causa confusão, e em vez do código de alguns caracteres, outros serão chamados. Vários símbolos estranhos aparecem na tela (ver Fig. 1)... Arroz. 1. Bloco de notas - problema de codificação Como lidar com isso? Na minha opinião A melhor opção- isto é para instalar um bloco de notas avançado, por exemplo Notepad++ ou Bred 3. Vejamos cada um deles com mais detalhes. Bloco de notas++ Site oficial: https://notepad-plus-plus.org/ Um dos melhores blocos de notas para iniciantes e profissionais. Prós: programa gratuito, suporta o idioma russo, funciona muito rapidamente, destacando código, abrindo todos os formatos de arquivo comuns, um grande número de opções permite que você personalize você mesmo. Em termos de codificações, geralmente há uma ordem completa aqui: há uma seção separada “Codificações” (ver Fig. 2). Tente alterar ANSI para UTF-8 (por exemplo). Depois de alterar a codificação, meu documento de texto tornou-se normal e legível - os hieróglifos desapareceram (ver Fig. 3)! Site oficial: http://www.astonshell.ru/freeware/bred3/ Outro ótimo programa desenvolvido para substituir completamente o bloco de notas padrão do Windows. Ele também funciona “facilmente” com muitas codificações, altera-as facilmente, suporta um grande número de formatos de arquivo e suporta novos sistemas operacionais Windows (8, 10). A propósito, Bred 3 é muito útil ao trabalhar com arquivos “antigos” salvos em formatos MS DOS. Quando outros programas mostram apenas hieróglifos, o Bred 3 os abre facilmente e permite que você trabalhe com eles com segurança (veja a Fig. 4). Se houver hieróglifos em vez de texto no Microsoft Word A primeira coisa que você precisa prestar atenção é o formato do arquivo. O fato é que a partir do Word 2007 novo formato- “docx” (anteriormente era apenas “doc”). Normalmente, novos formatos de arquivo não podem ser abertos no “antigo” Word, mas às vezes acontece que esses “novos” arquivos são abertos no programa antigo. Basta abrir as propriedades do arquivo e depois olhar a aba “Detalhes” (como na Figura 5). Desta forma você descobrirá o formato do arquivo (na Fig. 5 - o formato do arquivo “txt”). Se o formato arquivo docx- e você tem um Word antigo (abaixo da versão 2007) - então é só atualizar o Word para 2007 ou superior (2010, 2013, 2016). A seguir, ao abrir um arquivo, preste atenção (por padrão esta opção está sempre ativado, a menos, é claro, que você tenha “não entendo qual assembly”) - o Word perguntará novamente: em qual codificação abrir o arquivo (esta mensagem aparece a qualquer “sinal” de problemas ao abrir o arquivo, veja a Figura 5). Arroz. 6. Word - conversão de arquivo Na maioria das vezes, o Word determina automaticamente a codificação necessária, mas o texto nem sempre é legível. Você precisa definir o controle deslizante para a codificação desejada quando o texto se tornar legível. Às vezes você precisa adivinhar literalmente como um arquivo foi salvo para poder lê-lo. Arroz. 7. Word - o arquivo está normal (a codificação foi escolhida corretamente)! Alterando a codificação no navegador Quando o navegador detecta erroneamente a codificação de uma página da Internet, você verá exatamente os mesmos hieróglifos (veja a Figura 8). Para corrigir a exibição do site: altere a codificação. Isso é feito nas configurações do navegador: Assim, neste artigo foram analisados os casos mais comuns de aparecimento de hieróglifos associados a uma codificação definida incorretamente. Usando os métodos acima, você pode resolver todos os principais problemas de codificação incorreta. Acho que você já se deparou com explorações classificadas como Unicode mais de uma vez, procurou a codificação correta para exibir uma página e ficou satisfeito com os próximos truques aqui e ali. Você nunca sabe o que mais! Se você quiser descobrir quem começou toda essa bagunça e ainda está limpando até hoje, aperte os cintos e continue lendo. Como se costuma dizer, “a iniciativa é punível” e, como sempre, os americanos são os culpados de tudo. E foi assim. No início do apogeu da indústria de informática e da difusão da Internet, surgiu a necessidade de um sistema universal de representação de símbolos. E na década de 60 do século passado surgiu o ASCII - “American Standard Code for Information Interchange” (American Código Padrão para troca de informações), uma codificação de caracteres familiar de 7 bits. O último oitavo bit não utilizado foi deixado como bit de controle para personalizar a tabela ASCII para atender às necessidades de cada cliente de computador em uma região específica. Este bit possibilitou expandir a tabela ASCII para utilizar caracteres próprios para cada idioma. Os computadores foram fornecidos para vários países, onde já utilizavam sua própria tabela modificada. Mais tarde, porém, esse recurso se tornou uma dor de cabeça, já que a troca de dados entre computadores tornou-se bastante problemática. As novas páginas de código de 8 bits eram incompatíveis entre si - o mesmo código poderia significar vários caracteres diferentes. Para resolver este problema, a ISO (International Organization for Standardization) propôs uma nova tabela, nomeadamente “ISO 8859”. Este padrão foi posteriormente renomeado como UCS (“Conjunto de caracteres universal”). No entanto, quando o UCS foi lançado pela primeira vez, o Unicode já havia aparecido. Mas como as metas e objetivos de ambas as normas coincidiam, decidiu-se unir forças. Bem, o Unicode assumiu a difícil tarefa de dar a cada caractere uma designação única. Sobre este momento A versão mais recente do Unicode é 5.2. Quero avisá-lo - na verdade, a história com codificações é muito obscura. Fontes diferentes fornecem fatos diferentes, então você não deve focar em uma coisa, apenas estar ciente de como tudo foi formado e seguir os padrões modernos. Esperamos que não sejamos historiadores. Curso intensivo de UnicodeAntes de me aprofundar no assunto, gostaria de esclarecer o que é Unicode tecnicamente. Metas deste padrão Já sabemos, só falta consertar o hardware. Então, o que é Unicode? Simplificando, esta é uma forma de representar qualquer caractere como um código específico para todos os idiomas do mundo. Última versão O padrão contém cerca de 1.100.000 códigos, que ocupam espaço de U+0000 a U+10FFFF. Mas tenha cuidado aqui! Unicode define estritamente o que é um código para um caractere e como esse código será representado na memória. Os códigos de caracteres (por exemplo, 0041 para o caractere “A”) não possuem nenhum significado, mas existe uma lógica para representar esses códigos em bytes, isso é feito por codificações; O Unicode Consortium oferece os seguintes tipos de codificações, chamadas UTF (Unicode Transformation Formats). E aqui estão eles:
O análogo mais próximo do UTF-32 é a codificação UCS-4, mas hoje é usada com menos frequência. Apesar de UTF-8 e UTF-32 poderem representar pouco mais de dois bilhões de caracteres, optou-se por limitar-nos a pouco mais de um milhão por uma questão de compatibilidade com UTF-16. Todo o espaço de código é agrupado em 17 planos, cada um com 65.536 símbolos. Os símbolos usados com mais frequência estão localizados no plano base zero. Referido como BMP - MultiPlane Básico. Por uma questão de compatibilidade com versões anteriores, o Unicode teve que acomodar caracteres de codificações existentes. Mas aqui surge outro problema - existem muitas variantes de caracteres idênticos que precisam ser processados de alguma forma. Portanto, é necessária a chamada “normalização”, após a qual já é possível comparar duas strings. Existem 4 formas de normalização:
Agora vamos falar mais sobre essas palavras estranhas. Unicode define dois tipos de igualdade de strings - canônica e compatibilidade. A primeira envolve a decomposição de um símbolo complexo em várias figuras individuais, que como um todo formam o símbolo original. A segunda igualdade encontra o símbolo correspondente mais próximo. E a composição é a combinação de símbolos de diferentes partes, a decomposição é a ação oposta. Em geral, olhe o desenho, tudo vai se encaixar. Por motivos de segurança, a normalização deve ser feita antes da string ser submetida a qualquer filtro para verificação. Após esta operação, o tamanho do texto pode mudar, o que pode ter consequências negativas, mas falaremos mais sobre isso mais tarde. Em termos teóricos, só isso, ainda não falei muito, mas espero não ter perdido nada importante. Unicode é incrivelmente vasto, complexo e livros grossos são publicados nele, e é muito difícil explicar de forma concisa, acessível e completa os fundamentos de um padrão tão complicado. De qualquer forma, para uma compreensão mais profunda, você deve conferir os links laterais. Então, quando a imagem do Unicode ficar mais ou menos clara, podemos seguir em frente. Ilusão visualVocê provavelmente já ouviu falar sobre falsificação de IP/ARP/DNS e tem uma boa ideia do que é. Mas há também a chamada “falsificação visual” - este é o mesmo método antigo que os phishers usam ativamente para enganar as vítimas. Nesses casos, utiliza-se o uso de letras semelhantes, como “o” e “0”, “5” e “s”. Esta é a opção mais comum e simples, e é mais fácil de perceber. Um exemplo é o ataque de phishing de 2000 ao PayPal, que chegou a ser mencionado nas páginas do www.unicode.org. No entanto, isso tem pouca relevância para o nosso tópico Unicode. Para os mais avançados, apareceu no horizonte o Unicode, ou mais precisamente, o IDN, que é uma abreviatura de “Nomes de Domínio Internacionalizados”. O IDN permite o uso de caracteres do alfabeto nacional em nomes de domínio. Os registradores de nomes de domínio consideram isso uma coisa conveniente, dizem eles, disque Nome do domínio em sua língua nativa! No entanto, esta conveniência é muito questionável. Bem, ok, marketing não é o nosso assunto. Mas imagine como isso representa um refúgio para phishers, especialistas em SEO, cibercriminosos e outros espíritos malignos. Estou falando de um efeito chamado falsificação de IDN. Este ataque pertence à categoria de falsificação visual; na literatura inglesa também é chamado de “ataque homógrafo”, ou seja, ataques usando homógrafos (palavras com grafia idêntica). Sim, ao digitar letras, ninguém cometerá erros e não digitará um domínio deliberadamente falso. Mas na maioria das vezes, os usuários clicam em links. Se você quiser se convencer da eficácia e simplicidade do ataque, veja a foto. O IDNA2003 foi inventado como uma espécie de panacéia, mas já neste ano de 2010 o IDNA2008 entrou em vigor. O novo protocolo deveria resolver muitos dos problemas do jovem IDNA2003, mas introduziu novas oportunidades para ataques de falsificação. Problemas de compatibilidade surgem novamente - em alguns casos, o mesmo endereço em navegadores diferentes pode levar a servidores diferentes. A questão é que o Punycode pode ser convertido de diferentes maneiras para navegadores diferentes- tudo dependerá de quais especificações padrão são suportadas. Na figura, como você pode ver, temos um arquivo chamado evilexe. TXT. Mas isso é falso! Na verdade, o arquivo é chamado de eviltxt.exe. Que tipo de porcaria é essa entre parênteses, você pergunta? E este é o U+202E ou RIGHT-TO-LEFT OVERRIDE, o chamado Bidi (da palavra bidirecional) – um algoritmo Unicode para suportar idiomas como árabe, hebraico e outros. Estes últimos têm escrita da direita para a esquerda. Após inserir o caractere Unicode RLO, veremos tudo o que vem depois do RLO na ordem inversa. Como um exemplo este método da vida real, posso citar um ataque de falsificação no Mozilla Firfox - cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376. Ignorando filtros - estágio nº 1Hoje já se sabe que formulários longos (formato não mais curto) de UTF-8 não podem ser processados, pois esta é uma vulnerabilidade potencial. No entanto, os desenvolvedores de PHP não podem ser convencidos disso. Vamos descobrir o que é esse bug. Talvez você se lembre da filtragem incorreta e do utf8_decode(). Este é o caso que consideraremos com mais detalhes. Então temos este código PHP:
|

















Popular:
Novo
- Configurando detalhes adicionais e informações adicionais para detalhes adicionais da nomenclatura 1C e diferenças de informações
- O que fazer quando não há dados cadastrais
- Solicitação de seleção de dados (fórmulas) em MS EXCEL Seleção Excel por macro de condição
- E-mail temporário temporário, e-mail temporário, sites de e-mail, registro de mídia social
- O que fazer se o computador não vir o telefone através da porta USB
- Como instalar o Windows no Mac?
- Firmware de configuração do Asus rt n16
- Como descobrir o número de bits do sistema operacional e do processador no Windows
- Como desativar o Firewall do Windows: desativação e desativação completa de programas individuais. Como desativar completamente o firewall do Windows 7
- Conversor poderoso de arquivos HTML para Doc, PDF, Excel, JPEG, Texto usando o programa Total HTML Converter