Secțiuni de site
Alegerea editorului:
- Cum să eliminați complet Programul Avast pentru a elimina Avast
- Aplicație mobilă Aliexpress
- Dispunerea tastaturii QWERTY și AZERTY Versiuni speciale ale tastaturii Dvorak
- Insula Sao Vicente Insula Sao Vicente
- Regulile pe care le încălcăm Este în regulă să-ți pui coatele pe masă?
- Care unități flash USB sunt cele mai fiabile și mai rapide?
- Conectarea unui laptop la un televizor prin cablu USB pentru conectarea unui laptop la un televizor VGA
- Schimbarea interfeței Steam - de la imagini simple la întreaga prezentare pe ecran Design nou steam
- Cum să anulați un abonament Megogo la televizor: instrucțiuni detaliate Cum să vă dezabonați de la abonamentele Megogo
- Cum să partiționați un disc cu Windows instalat fără a pierde date Partiționați discul 7
Publicitate
|
A fost prima dată când am văzut așa ceva - fișierele și folderele de pe unitatea flash au dispărut, iar în locul lor au apărut fișiere cu nume de neînțeles sub formă de „kryakozyabriks”, să le numim hieroglife. Unitatea flash a fost deschisă cu standard folosind Windowsși în plus a existat, din păcate, acest lucru nu a dat rezultate pozitive.
Toate fișierele de pe unitatea flash au dispărut, cu excepția unuia. Au apărut mai multe fișiere cu nume ciudate: &, t, n-& etc. Fișierele de pe unitatea flash au dispărut, dar Windows arată că spațiul liber este ocupat. Acest lucru sugerează că, deși fișierele care ne interesează nu sunt afișate, ele se află pe unitatea flash.
Deși fișierele au dispărut, spațiul este ocupat. ÎN caz concret, 817 MB ocupați Primul gând despre cauza a ceea ce s-a întâmplat este efectul virusului. Anterior, când a existat un virus, a fost folosit managerul de fișiere FAR manager, care, de regulă, vede toate fișierele (ascunse și de sistem). Cu toate acestea, de data aceasta, managerul FAR a văzut doar ceea ce a făcut Windows Explorer standard...
Nici managerul FAR nu a putut vedea fișierele „pierdute”. Deoarece Windows nu vede fișierele lipsă, nu încearcă trucul de a schimba atributele fișierelor folosind linie de comandă iar comenzile atrib -S -H /S /D.
În această situație, ca experiment, am decis să folosesc sistemul de operare Bazat pe Linux. În acest caz particular, a fost folosit un disc cu un sistem de operare sistem Ubuntu 10.04.3 (mai multe despre Ubuntu și de unde să-l descărcați). Important! Nu este nevoie să instalați Ubuntu pe computer - trebuie doar să porniți de pe un CD, la fel ca și cu . După pornirea Ubuntu, va apărea desktopul și puteți lucra cu foldere și fișiere exact în același mod ca în Windows.
După cum era de așteptat, Ubuntu a văzut mai multe fișiere comparativ cu Windows.
Ubuntu afișează și acele fișiere care nu erau vizibile din Windows (pe care se poate da clic) Apoi, pentru a nu te deranja cu atributele fișierului, au fost parcurși pașii de bază: toate fișierele afișate au fost selectate și copiate în disc local„D” (desigur, puteți copia fișiere în disc de sistem„C”) Acum puteți porni din nou Windows și puteți verifica ce s-a întâmplat.
Acum Windows vede mai multe fișiere Word. Vă rugăm să rețineți că și numele fișierelor sunt afișate corect Din păcate, problema nu este rezolvată, deoarece erau în mod clar mai multe fișiere pe unitatea flash (judecând după volumul de 817 MB) decât am putut extrage. Din acest motiv, să încercăm să verificăm unitatea flash pentru erori. Depanarea erorilor unității flashPentru a găsi și remedia erorile de pe discuri, Windows are un utilitar standard. Pasul 1. Faceți clic dreapta pe pictograma unității flash și selectați comanda „Proprietăți”.
Pasul 2. Accesați fila „Service” și faceți clic pe butonul „Run check”.
Pasul 3. Faceți clic pe butonul „Launch”.
Dupa verificare si reparare erori de sistem, va apărea un mesaj corespunzător.
Mesaj: „Au fost găsite și remediate unele erori” După eliminarea erorilor, fișierele cu hieroglife au dispărut, iar în directorul rădăcină al unității flash au apărut folder ascuns cu numele GĂSIT.000.
În interiorul folderului FOUND.000 erau 264 de fișiere cu extensia CHK. Fișierele cu extensia CHK pot stoca fragmente de fișiere diverse tipuri, extras din hard disk-uriși unități flash folosind utilitarele ScanDisk sau CHKDISK. Dacă toate fișierele de pe unitatea flash au fost de același tip, de exemplu, Documente Word cu extensia docx, apoi în manager de fișiere Comandant total selectați toate fișierele și apăsați combinația de taste Ctrl + M (Fișiere - Redenumire grup). Indicăm ce extensie să căutați și în ce să o schimbați.
În acest caz particular, știam doar că unitatea flash conține documente Word și fișiere cu prezentări Power Point. Schimbarea la întâmplare a extensiilor este foarte problematică, deci este mai bine să le utilizați programe specializate— ei înșiși vor determina ce tip de date sunt stocate în fișier. Un astfel de program este utilitate gratuită, care nu necesită instalare pe computer. Specificați folderul sursă (am aruncat fișierele CHK în hard disk). În continuare, am ales opțiunea în care fișierele cu extensii diferite vor fi plasate în foldere diferite.
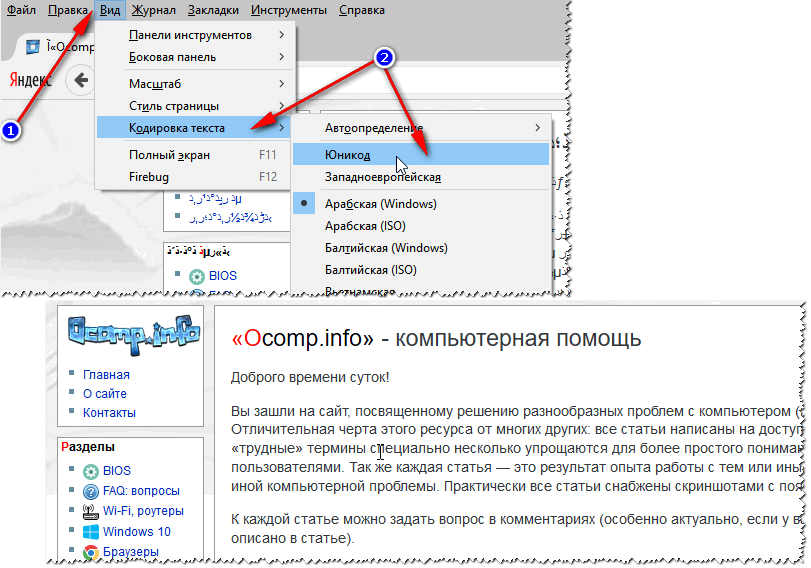
Tot ce trebuie să faceți este să faceți clic pe „Start” Ca rezultat al utilitarului, au apărut trei foldere: Conținutul a opt fișiere a rămas nerecunoscut. Cu toate acestea, sarcina principală a fost finalizată, documentele și fotografiile Word au fost restaurate. Dezavantajul este că nu a fost posibil să se restabilească nume de fișiere similare, așa că va trebui, evident, să te chinui cu redenumirea documentelor Word. În ceea ce privește fișierele cu imagini, vor funcționa și nume precum FILE0001.jpg, FILE0002.jpg etc. Întrebarea utilizatorului Buna ziua. Vă rog să-mi spuneți de ce unele pagini din browser-ul meu afișează hieroglife, pătrate și cine știe ce (nimic nu poate fi citit) în loc de text. Acest lucru nu s-a întâmplat înainte. Mulţumesc anticipat... Bună ziua! Într-adevăr, uneori, când deschideți o pagină de internet, în loc de text, sunt afișate diverse „kryakozabry” (cum le numesc eu) și este imposibil să o citiți. Acest lucru se întâmplă din cauza faptului că textul de pe pagină este scris într-o codificare (puteți afla mai multe despre aceasta din), iar browserul încearcă să-l deschidă într-o alta. Din cauza acestei discrepanțe, în loc de text există un set de caractere de neînțeles. Să încercăm să reparăm asta... BrowserDe fapt, înainte Internet Explorer de multe ori au dat fisuri similare, 👉 (Chrome, browser Yandex, Opera, Firefox) - determină codificarea destul de bine și greșesc foarte rar. 👌 Voi spune și mai mult, în unele versiuni ale browserului, alegerea codificării a fost deja eliminată, iar pentru a configura „manual” acest parametru trebuie să descărcați suplimente sau să intrați în jungla setărilor pentru 10 căpușe. . Și așa, să presupunem că browserul a detectat incorect codificarea și ați văzut următoarele (ca în captura de ecran de mai jos 👇).
👉 Apropo! Cel mai adesea, apare confuzie între codările UTF (Unicode) și Windows-1251 (majoritatea site-urilor în limba rusă sunt realizate în aceste codificări).
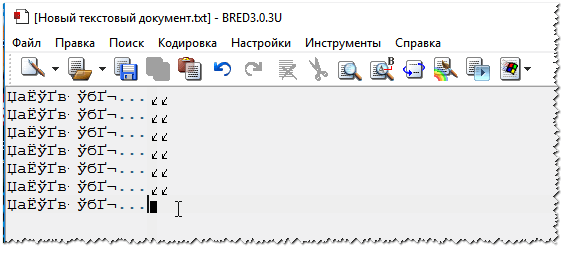
Un alt sfat: dacă nu găsiți cum să schimbați codarea în browser (și, în general, este nerealist să dați instrucțiuni pentru fiecare browser!), vă recomand să încercați să deschideți pagina într-un browser diferit. Foarte des, un alt program deschide pagina așa cum ar trebui. Documente textO mulțime de întrebări despre crackeri sunt puse la deschiderea unor documente text. Mai ales cele vechi, de exemplu, când citesc Readme într-un program din secolul trecut (să zicem, pentru jocuri). Desigur, multe notepad-uri moderne pur și simplu nu pot citi codarea DOS care a fost folosită anterior. Pentru a rezolva această problemă, vă recomand să utilizați editorul Bread 3. Crescut 3 Un bloc de note text simplu și convenabil. Un lucru de neînlocuit atunci când trebuie să lucrați cu fișiere text vechi. Bred 3 vă permite să schimbați codarea cu un singur clic și să faceți textul care nu poate fi citit! Pe lângă fișierele text, acceptă o varietate destul de mare de documente. In general il recomand! ✌ Încearcă să-l deschizi pe al tău în Bred 3 document text(cu care sunt probleme). Un exemplu este afișat în captura de ecran de mai jos.
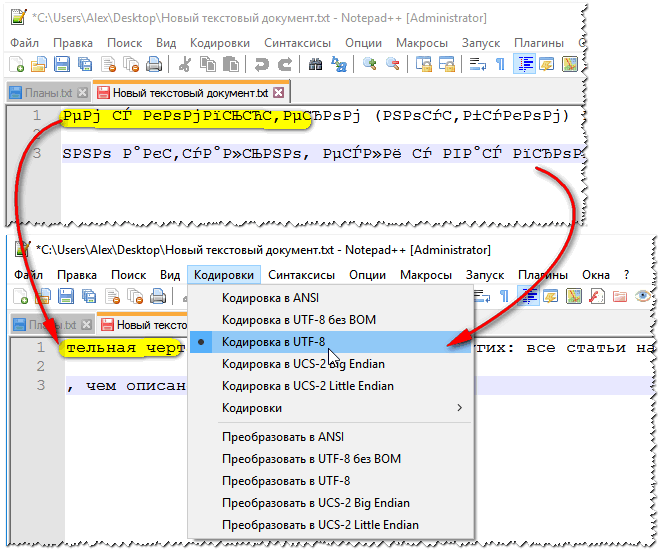
Un alt bloc de note - Notepad++ - este, de asemenea, potrivit pentru lucrul cu fișiere text cu diferite codificări. În general, desigur, este mai potrivit pentru programare, deoarece... Suportă diverse lumini de fundal pentru citirea mai ușoară a codului. Un exemplu de modificare a codificării este prezentat mai jos: pentru a citi textul, în exemplul de mai jos, a fost suficient să schimbați codificarea ANSI în UTF-8.
Foarte des, problema cu fisurile în Word se datorează faptului că cele două formate sunt confuze Doc și Docx. Cert este că din 2007 Word (dacă nu mă înșel) a introdus formatul Docx(vă permite să comprimați documentul mai puternic decât Doc și îl protejează mai fiabil). Deci, dacă aveți un Word vechi care nu acceptă acest format, atunci când deschideți un document în Docx, veți vedea hieroglife și nimic mai mult. Există două soluții: De asemenea, atunci când deschideți orice document în Word (a cărui codare el „se îndoiește”), vă oferă posibilitatea de a-l specifica singur. Un exemplu este prezentat în imaginea de mai jos, încercați să selectați:
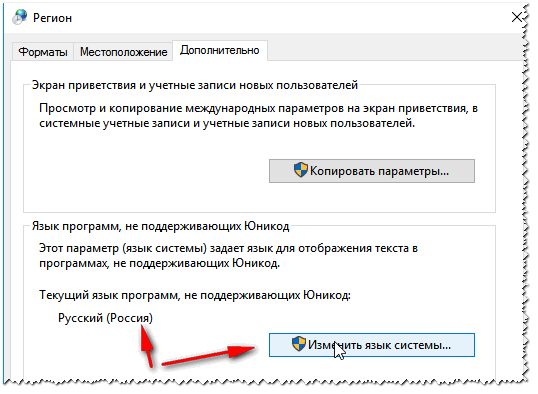
Se întâmplă ca o fereastră sau un meniu dintr-un program să fie afișate cu hieroglife (desigur, este imposibil să citiți sau să înțelegeți ceva). Regiuni și limbi în Windows Locație - Rusia Și în filă „În plus” setați limba sistemului „Rusă (Rusia)” . După aceasta, salvați setările și reporniți computerul. Apoi verificați din nou dacă interfața programului dorit este afișată normal.
Și, în sfârșit, acest lucru este probabil evident pentru mulți, și totuși unii deschid anumite fișiere în programe care nu sunt destinate acestui lucru: de exemplu, într-un bloc de note obișnuit încearcă să citească un fișier DOCX sau PDF. Bineînțeles, în acest caz, în loc de text, veți urmări pe biscuiți acele programe pentru care sunt concepute; de acest tip fișier (WORD 2016+ și Adobe Reader pentru exemplul de mai sus). Probabil că fiecare utilizator de PC a întâmpinat o problemă similară: deschideți o pagină de Internet sau un document Microsoft Word- și în loc de text vezi hieroglife (diverse „kryakozabry”, litere necunoscute, numere etc. (ca în imaginea din stânga...)). Este bine dacă acest document (cu hieroglife) nu este deosebit de important pentru tine, dar dacă trebuie să-l citești?! Destul de des, mi se pun întrebări similare și solicitări de ajutor pentru deschiderea unor astfel de texte. În acest scurt articol vreau să mă uit la cele mai populare motive pentru apariția hieroglifelor (și, desigur, să le elimin). Hieroglife în fișierele text (.txt) Cea mai populară problemă. Ideea este că fișier text(de obicei în format txt, dar sunt și formate: php, css, info etc.) pot fi salvate în diverse codificări. O codificare este un set de caractere necesare pentru a se asigura că textul este scris într-un anumit alfabet (inclusiv numere și caractere speciale). Mai multe detalii despre asta aici: https://ru.wikipedia.org/wiki/Character_set Cel mai adesea, se întâmplă un lucru: documentul este pur și simplu deschis într-o codificare greșită, ceea ce provoacă confuzie, iar în loc de codul unor caractere, altele vor fi apelate. Pe ecran apar diverse simboluri ciudate (vezi Fig. 1)... Orez. 1. Notepad - problemă de codificare Cum să te descurci cu asta? În opinia mea cea mai buna varianta- aceasta este pentru a instala un notepad avansat, de exemplu Notepad++ sau Bred 3. Să ne uităm la fiecare dintre ele mai detaliat. Notepad++ Site oficial: https://notepad-plus-plus.org/ Unul dintre cele mai bune blocnote atât pentru începători, cât și pentru profesioniști. Pro: program gratuit, acceptă limba rusă, funcționează foarte rapid, evidențierea codului, deschiderea tuturor formatelor de fișiere comune, un număr mare de opțiuni vă permit să-l personalizați pentru dvs. În ceea ce privește codificările, aici există în general o ordine completă: există o secțiune separată „Codificări” (vezi Fig. 2). Încercați doar să schimbați ANSI în UTF-8 (de exemplu). După ce am schimbat codificarea, documentul meu text a devenit normal și lizibil - hieroglifele au dispărut (vezi Fig. 3)! Site oficial: http://www.astonshell.ru/freeware/bred3/ Un alt program grozav conceput pentru a înlocui complet blocnotesul standard în Windows. De asemenea, funcționează „cu ușurință” cu multe codificări, le schimbă cu ușurință, acceptă un număr mare de formate de fișiere și acceptă noile sisteme de operare Windows (8, 10). Apropo, Bred 3 este foarte util atunci când lucrați cu fișiere „vechi” salvate în formate MS DOS. Când alte programe arată doar hieroglife, Bred 3 le deschide cu ușurință și vă permite să lucrați calm cu ele (vezi Fig. 4). Dacă există hieroglife în loc de text în Microsoft Word Primul lucru la care trebuie să acordați atenție este formatul fișierului. Cert este că începând cu Word 2007 nou format- „docx” (anterior era doar „doc”). De obicei, formatele noi de fișiere nu pot fi deschise în „vechiul” Word, dar uneori se întâmplă ca aceste fișiere „noi” să se deschidă în vechiul program. Doar deschideți proprietățile fișierului și apoi uitați-vă la fila „Detalii” (ca în Figura 5). În acest fel veți afla formatul fișierului (în Fig. 5 - formatul fișierului „txt”). Dacă formatul fișier docx- și aveți un Word vechi (sub versiunea 2007) - apoi actualizați doar Word la 2007 sau o versiune ulterioară (2010, 2013, 2016). Apoi, când deschideți un fișier, acordați atenție (în mod implicit această opțiune este întotdeauna activat, cu excepția cazului în care, desigur, aveți „nu înțeleg ce asamblare”) - Word vă va întreba din nou: în ce codificare să deschideți fișierul (acest mesaj apare la orice „indiciu” de probleme la deschiderea fișierului, vezi Fig. 5). Orez. 6. Word - conversie fișier Cel mai adesea, Word determină automat codarea necesară, dar textul nu este întotdeauna lizibil. Trebuie să setați glisorul la codificarea dorită atunci când textul devine lizibil. Uneori, trebuie să ghiciți literalmente cum a fost salvat fișierul pentru a-l citi. Orez. 7. Word - fisierul este normal (codarea este aleasa corect)! Modificarea codificării în browser Când browserul detectează în mod eronat codificarea unei pagini de Internet, veți vedea exact aceleași hieroglife (vezi Figura 8). Pentru a remedia afișarea site-ului: modificați codificarea. Acest lucru se face în setările browserului: Astfel, în acest articol au fost analizate cele mai frecvente cazuri de apariție a hieroglifelor asociate cu o codificare definită incorect. Folosind metodele de mai sus, puteți rezolva toate problemele principale cu codificarea incorectă. Cred că ați întâlnit exploit-uri care sunt clasificate ca Unicode de mai multe ori, ați căutat codificarea potrivită pentru a afișa o pagină și ați fost mulțumit de următoarele trucuri ici și colo. Nu știi niciodată ce altceva! Dacă doriți să aflați cine a început toată această mizerie și încă o curăță până în ziua de azi, puneți-vă centurile de siguranță și citiți mai departe. După cum se spune, „inițiativa este pedepsită” și, ca întotdeauna, americanii sunt de vină pentru tot. Și a fost așa. În zorii zilei de glorie a industriei computerelor și a răspândirii internetului, a apărut nevoia unui sistem universal de reprezentare a simbolurilor. Și în anii 60 ai secolului trecut, a apărut ASCII - „Codul standard american pentru schimbul de informații” (American Cod standard pentru schimbul de informații), o codificare familiară de caractere pe 7 biți. Ultimul al optulea bit neutilizat a fost lăsat ca bit de control pentru a personaliza tabelul ASCII pentru a se potrivi nevoilor fiecărui client de computer dintr-o anumită regiune. Acest bit a făcut posibilă extinderea tabelului ASCII pentru a utiliza propriile caractere pentru fiecare limbă. Calculatoarele au fost furnizate în multe țări, unde deja își foloseau propriul tabel modificat. Dar mai târziu această caracteristică a devenit o durere de cap, deoarece schimbul de date între computere a devenit destul de problematic. Noile pagini de coduri de 8 biți erau incompatibile între ele - același cod ar putea însemna mai multe caractere diferite. Pentru a rezolva această problemă, ISO (International Organization for Standardization) a propus un nou tabel, și anume „ISO 8859”. Acest standard a fost redenumit ulterior UCS („Setul de caractere universal”). Cu toate acestea, în momentul în care UCS a fost lansat pentru prima dată, a apărut Unicode. Dar, deoarece scopurile și obiectivele ambelor standarde au coincis, s-a decis unirea forțelor. Ei bine, Unicode și-a asumat sarcina dificilă de a oferi fiecărui personaj o denumire unică. Pe în acest moment Cea mai recentă versiune de Unicode este 5.2. Vreau să vă avertizez - de fapt, povestea cu codificări este foarte tulbure. Surse diferite oferă fapte diferite, așa că nu ar trebui să vă concentrați pe un singur lucru, doar să fiți conștienți de modul în care s-a format totul și să urmați standardele moderne. Sper că nu suntem istorici. Curs rapid UnicodeÎnainte de a pătrunde în subiect, aș dori să clarific în ce se află Unicode tehnic. Goluri acest standardȘtim deja, tot ce rămâne este să reparăm hardware-ul. Deci, ce este Unicode? Pur și simplu, aceasta este o modalitate de a reprezenta orice caracter ca un cod specific pentru toate limbile lumii. Ultima versiune Standardul conține aproximativ 1.100.000 de coduri, care ocupă spațiu de la U+0000 la U+10FFFF. Dar fii atent aici! Unicode definește strict ce este un cod pentru un caracter și cum va fi reprezentat acel cod în memorie. Codurile de caractere (de exemplu, 0041 pentru caracterul „A”) nu au nicio semnificație, dar există o logică pentru reprezentarea acestor coduri în octeți; Consorțiul Unicode oferă următoarele tipuri de codificări, numite UTF (Unicode Transformation Formats). Și iată-le:
Cel mai apropiat analog al UTF-32 este codificarea UCS-4, dar astăzi este folosit mai rar. În ciuda faptului că UTF-8 și UTF-32 pot reprezenta puțin mai mult de două miliarde de caractere, s-a decis să ne limităm la puțin peste un milion de dragul compatibilității cu UTF-16. Întregul spațiu de cod este grupat în 17 planuri, fiecare cu 65.536 de simboluri. Cele mai frecvent utilizate simboluri sunt situate în planul de bază zero. Denumit BMP - Basic MultiPlane. De dragul compatibilității cu versiunea anterioară, Unicode a trebuit să găzduiască caractere din codificările existente. Dar aici apare o altă problemă - există multe variante de caractere identice care trebuie procesate cumva. Prin urmare, este nevoie de așa-numita „normalizare”, după care este deja posibilă compararea a două șiruri. Există 4 forme de normalizare:
Acum să vorbim mai multe despre aceste cuvinte ciudate. Unicode definește două tipuri de egalitate de șiruri - canonică și compatibilitate. Primul implică descompunerea unui simbol complex în mai multe figuri individuale, care, în ansamblu, formează simbolul original. A doua egalitate găsește simbolul cel mai apropiat. Și compoziția este combinația de simboluri din diferite părți, descompunerea este acțiunea opusă. În general, uită-te la desen, totul va cădea la loc. Din motive de securitate, normalizarea ar trebui făcută înainte ca șirul să fie trimis la orice filtre pentru verificare. După această operație, dimensiunea textului se poate modifica, ceea ce poate avea consecințe negative, dar mai multe despre asta mai târziu. Din punct de vedere teorie, asta e tot, nu am spus prea multe încă, dar sper că nu am omis nimic important. Unicode este incredibil de vast, complex, cărți groase sunt publicate pe el și este foarte dificil să explici în mod concis, accesibil și complet elementele de bază ale unui standard atât de greoi. În orice caz, pentru o înțelegere mai profundă, ar trebui să verificați linkurile laterale. Deci, când imaginea cu Unicode a devenit mai mult sau mai puțin clară, putem merge mai departe. Iluzie vizualăProbabil ați auzit despre falsificarea IP/ARP/DNS și aveți o idee bună despre ce este. Dar există și așa-numita „falsificare vizuală” - aceasta este aceeași metodă veche pe care phisher-ii o folosesc în mod activ pentru a înșela victimele. În astfel de cazuri, se utilizează litere similare, cum ar fi „o” și „0”, „5” și „s”. Aceasta este cea mai comună și simplă opțiune și este mai ușor de observat. Un exemplu este atacul de phishing din 2000 asupra PayPal, care a fost chiar menționat pe paginile www.unicode.org. Cu toate acestea, acest lucru nu are nicio relevanță pentru subiectul nostru Unicode. Pentru băieții mai avansați, Unicode a apărut la orizont, sau mai exact, IDN, care este o abreviere pentru „Internationalized Domain Names”. IDN permite utilizarea caracterelor alfabetului național în numele de domenii. Registratorii numelor de domeniu poziționează acest lucru ca un lucru convenabil, spun ei, apelează nume de domeniuîn limba ta maternă! Cu toate acestea, această comoditate este foarte discutabilă. Ei bine, marketingul nu este subiectul nostru. Dar imaginați-vă ce refugiu este acesta pentru phishing, specialiști SEO, cybersquatters și alte spirite rele. Vorbesc despre un efect numit IDN spoofing. Acest atac aparține categoriei de falsificare vizuală în literatura engleză este numit și „atac omograf”, adică atacuri folosind omografe (cuvinte care sunt identice în ortografie). Da, atunci când tastați litere, nimeni nu va greși și nu va introduce un domeniu în mod deliberat fals. Dar cel mai adesea, utilizatorii dau clic pe linkuri. Dacă vrei să te convingi de eficacitatea și simplitatea atacului, atunci uită-te la imagine. IDNA2003 a fost inventat ca un fel de panaceu, dar deja anul acesta, 2010, a intrat în vigoare IDNA2008. Noul protocol trebuia să rezolve multe dintre problemele tânărului IDNA2003, dar a introdus noi oportunități pentru atacuri de falsificare. Problemele de compatibilitate apar din nou - în unele cazuri, aceeași adresă în browsere diferite poate duce la servere diferite. Ideea este că Punycode poate fi convertit în diferite moduri pentru browsere diferite- totul va depinde de specificațiile standard acceptate. În figură, după cum puteți vedea, avem un fișier numit evilexe. TXT. Dar asta este fals! Fișierul se numește de fapt eviltxt.exe. Ce fel de porcărie este asta între paranteze, întrebi? Și acesta este U+202E sau RIGHT-TO-LEFT OVERRIDE, așa-numitul Bidi (din cuvântul bidirecțional) - un algoritm Unicode pentru a accepta limbi precum arabă, ebraică și altele. Aceștia din urmă au scris de la dreapta la stânga. După introducerea caracterului Unicode RLO, vom vedea tot ce urmează după RLO în ordine inversă. Ca exemplu această metodă din viața reală pot cita un atac de falsificare în Mozilla Firfox - cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376. Filtre de ocolire - etapa nr. 1Astăzi se știe deja că formele lungi (forma care nu este cea mai scurtă) ale UTF-8 nu pot fi procesate, deoarece aceasta este o potențială vulnerabilitate. Cu toate acestea, dezvoltatorii PHP nu pot fi convinși de acest lucru. Să ne dăm seama care este acest bug. Poate vă amintiți despre filtrarea incorectă și utf8_decode(). Acesta este cazul pe care îl vom analiza mai detaliat. Deci avem acest cod PHP:
|

















| Citire: |
|---|
Nou
- Aplicație mobilă Aliexpress
- Dispunerea tastaturii QWERTY și AZERTY Versiuni speciale ale tastaturii Dvorak
- Insula Sao Vicente Insula Sao Vicente
- Regulile pe care le încălcăm Este în regulă să-ți pui coatele pe masă?
- Care unități flash USB sunt cele mai fiabile și mai rapide?
- Conectarea unui laptop la un televizor prin cablu USB pentru conectarea unui laptop la un televizor VGA
- Schimbarea interfeței Steam - de la imagini simple la întreaga prezentare pe ecran Design nou steam
- Cum să anulați un abonament Megogo la televizor: instrucțiuni detaliate Cum să vă dezabonați de la abonamentele Megogo
- Cum să partiționați un disc cu Windows instalat fără a pierde date Partiționați discul 7
- De ce editorii nu pot edita toate paginile