Secciones del sitio
Selección del editor:
- Salida de parte de un sprite html de imagen
- Configuración de detalles adicionales e información adicional para la nomenclatura 1c detalles adicionales y diferencias de información
- Qué hacer cuando no hay datos de registro
- Solicitud de selección de datos (fórmulas) en MS EXCEL Selección de Excel por macro de condición
- Correo electrónico temporal temporal de una sola vez Correo electrónico temporal, sitios de correo, registro en redes sociales
- Qué hacer si la computadora no ve el teléfono a través del puerto USB
- ¿Cómo instalar Windows en Mac?
- Firmware de configuración de Asus rt n16
- Cómo averiguar el bitness del sistema operativo y el procesador en Windows
- Cómo desactivar el Firewall de Windows: desactivación completa y deshabilitación de programas individuales Cómo desactivar completamente el firewall de Windows 7
Publicidad
| Seleccionar codificación de texto al abrir y guardar archivos. Qué hacer si hay jeroglíficos en lugar de texto (en Word, navegador o documento de texto) El documento de texto se abre con jeroglíficos |
|
Esta fue la primera vez que vi algo como esto: los archivos y carpetas de la unidad flash desaparecieron y en su lugar aparecieron archivos con nombres incomprensibles en forma de "kryakozyabriks", llamémoslos jeroglíficos. La unidad flash se abrió con estándar. usando windows Y además, lamentablemente, esto no dio resultados positivos.
Todos los archivos de la unidad flash han desaparecido, excepto uno. Aparecieron varios archivos con nombres extraños: &, t, n-&, etc. Los archivos de la unidad flash han desaparecido, pero Windows muestra que el espacio libre está ocupado. Esto sugiere que aunque los archivos que nos interesan no se muestran, están ubicados en la unidad flash.
Aunque los archivos han desaparecido, el espacio está ocupado. EN caso específico, 817 MB ocupados El primer pensamiento sobre la causa de lo sucedido es el efecto del virus. Anteriormente, cuando aparecía un virus, se utilizaba el administrador de archivos FAR Manager, que, por regla general, ve todos los archivos (ocultos y del sistema). Sin embargo, esta vez, el administrador FAR solo vio lo que hizo el Explorador de Windows estándar...
Ni siquiera el administrador de las FAR pudo ver los archivos “perdidos” Dado que Windows no ve los archivos faltantes, no intenta cambiar los atributos del archivo usando línea de comando y los comandos attrib -S -H /S /D.
En esta situación, a modo de experimento, decidí utilizar el sistema operativo en Basado en Linux. En este caso particular se utilizó un disco con un sistema operativo sistema ubuntu 10.04.3 (más sobre Ubuntu y dónde descargarlo). ¡Importante! No es necesario instalar Ubuntu en su computadora; simplemente inicie desde un CD, tal como lo hace con . Después de iniciar Ubuntu, aparecerá el escritorio y podrá trabajar con carpetas y archivos exactamente de la misma manera que en Windows.
Como era de esperar, Ubuntu vio más archivos en comparación con Windows.
Ubuntu también muestra aquellos archivos que no eran visibles desde Windows (se puede hacer clic) A continuación, para no molestarse con los atributos de los archivos, se tomaron pasos básicos: todos los archivos mostrados se seleccionaron y copiaron a disco local“D” (por supuesto, puedes copiar archivos a disco del sistema"C") Ahora puedes iniciar Windows nuevamente y comprobar qué sucedió.
Ahora Windows ve varios archivos de Word. Tenga en cuenta que los nombres de los archivos también se muestran correctamente Desafortunadamente, el problema no se resuelve, ya que claramente había más archivos en la unidad flash (a juzgar por el volumen de 817 MB) de los que pudimos extraer. Por este motivo, intentemos comprobar si hay errores en la unidad flash. Solución de problemas de errores de la unidad flashPara buscar y corregir errores en los discos, Windows tiene una utilidad estándar. Paso 1. Haga clic derecho en el icono de la unidad flash y seleccione el comando "Propiedades".
Paso 2. Vaya a la pestaña "Servicio" y haga clic en el botón "Ejecutar verificación".
Paso 3. Haga clic en el botón "Iniciar".
Después de comprobar y arreglar errores del sistema, aparecerá el mensaje correspondiente.
Mensaje: "Se han encontrado y solucionado algunos errores" Después de eliminar los errores, los archivos con jeroglíficos desaparecieron y aparecieron en el directorio raíz de la unidad flash. carpeta oculta con el nombre FOUND.000.
Dentro de la carpeta FOUND.000 había 264 archivos con la extensión CHK. Los archivos con la extensión CHK pueden almacenar fragmentos de archivos varios tipos, extraído de unidades de disco duro y unidades flash utilizando las utilidades ScanDisk o CHKDISK. Si todos los archivos en la unidad flash fueran del mismo tipo, por ejemplo, documentos de palabra con la extensión docx, luego en administrador de archivos Comandante total seleccione todos los archivos y presione la combinación de teclas Ctrl + M (Archivos - Cambio de nombre de grupo). Te indicamos qué extensión buscar y a qué cambiarla.
En este caso particular, sólo sabía que la unidad flash contenía documentos de Word y archivos con presentaciones de Power Point. Cambiar extensiones al azar es muy problemático, por lo que es mejor usar programas especializados— ellos mismos determinarán qué tipo de datos se almacenan en el archivo. Uno de esos programas es utilidad gratuita, que no requiere instalación en su computadora. Especifique la carpeta de origen (dejé los archivos CHK en disco duro). A continuación, elegí la opción en la que los archivos con diferentes extensiones se colocarían en diferentes carpetas.
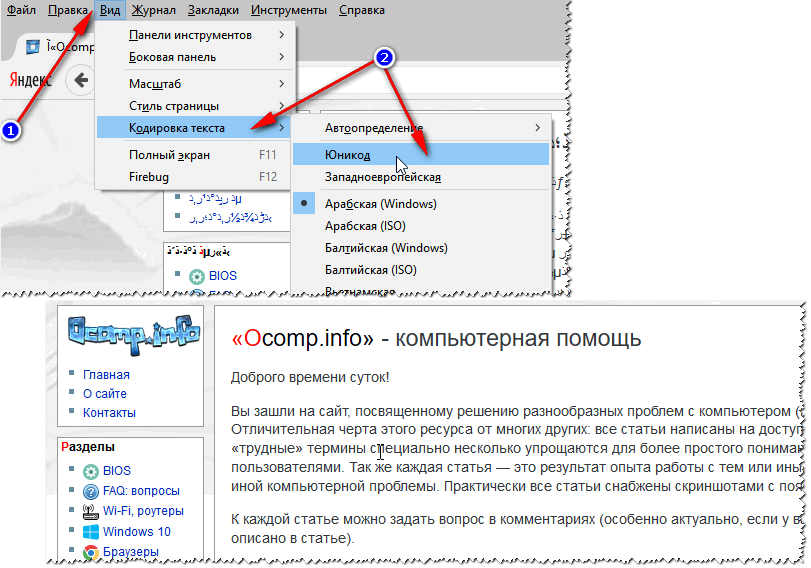
Todo lo que tienes que hacer es hacer clic en "Iniciar" Como resultado de la utilidad, aparecieron tres carpetas: El contenido de ocho expedientes permaneció desconocido. Sin embargo, la tarea principal se completó: se restauraron documentos de Word y fotografías. La desventaja es que no fue posible restaurar nombres de archivos similares, por lo que obviamente tendrás que jugar con el cambio de nombre de los documentos de Word. En cuanto a archivos con imágenes, también funcionarán nombres como FILE0001.jpg, FILE0002.jpg, etc. Pregunta de usuario Hola. Dígame por qué algunas páginas de mi navegador muestran jeroglíficos, cuadrados y no entiendo qué (no se puede leer nada) en lugar de texto. Esto no sucedió antes. Gracias de antemano... ¡Buen día! De hecho, a veces, al abrir una página de Internet, en lugar de texto, se muestran varios "kryakozabry" (como yo los llamo) y es imposible leerlos. Esto sucede debido al hecho de que el texto de la página está escrito en una codificación (puede obtener más información sobre esto en) y el navegador intenta abrirlo en otra. Debido a esta discrepancia, en lugar de texto aparece un conjunto de caracteres incomprensibles. Intentemos arreglar esto... NavegadorEn realidad, antes explorador de Internet a menudo daban cracks similares, 👉 (Chrome, navegador Yandex, Opera, Firefox): determinan bastante bien la codificación y cometen errores muy raramente. 👌 Diré aún más, en algunas versiones del navegador ya se ha eliminado la opción de codificación, y para configurar "manualmente" este parámetro es necesario descargar complementos o adentrarse en la jungla de configuraciones durante 10 ticks. . Entonces, supongamos que el navegador detectó incorrectamente la codificación y vio lo siguiente (como en la captura de pantalla a continuación 👇).
👉 ¡Por cierto! La mayoría de las veces, se produce confusión entre las codificaciones UTF (Unicode) y Windows-1251 (la mayoría de los sitios en ruso se crean con estas codificaciones).
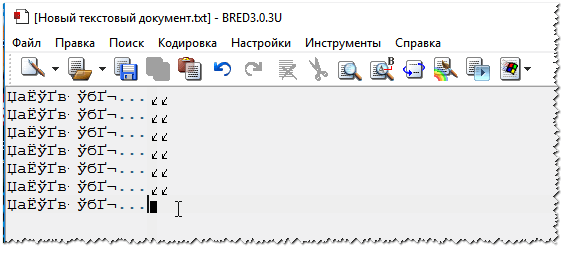
Otro consejo: si no encuentras cómo cambiar la codificación en tu navegador (¡y generalmente no es realista dar instrucciones para cada navegador!), te recomiendo intentar abrir la página en un navegador diferente. Muy a menudo, otro programa abre la página como debería. Documentos de textoAl abrir algunos documentos de texto, surgen muchas preguntas sobre los crackers. Especialmente los antiguos, por ejemplo, al leer el Léame en algún programa del siglo pasado (digamos, para juegos). Por supuesto, muchos blocs de notas modernos simplemente no pueden leer la codificación DOS que se usaba anteriormente. Para resolver este problema, recomiendo usar el editor Bread 3. Criado 3 Un bloc de notas de texto sencillo y práctico. Algo insustituible cuando necesitas trabajar con archivos de texto antiguos. ¡Bred 3 le permite cambiar la codificación con un solo clic y hacer legible el texto ilegible! Además de los archivos de texto, admite una variedad bastante amplia de documentos. En general lo recomiendo! ✌ Intenta abrir el tuyo en Bred 3 Documento de texto(con el que hay problemas). En mi captura de pantalla a continuación se muestra un ejemplo.
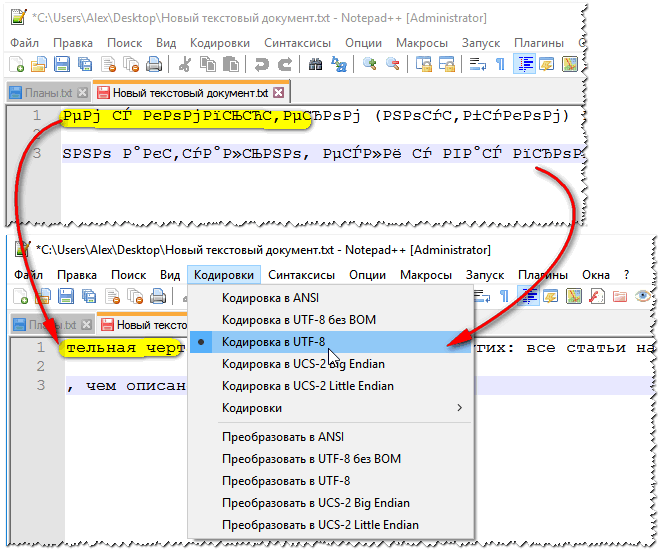
Otro bloc de notas, Notepad++, también es adecuado para trabajar con archivos de texto de varias codificaciones. En general, por supuesto, es más adecuado para programación, porque... Admite varias luces de fondo para facilitar la lectura de códigos. A continuación se muestra un ejemplo de cómo cambiar la codificación: para leer el texto, en el siguiente ejemplo, fue suficiente cambiar la codificación ANSI a UTF-8.
Muy a menudo el problema de las grietas en Word se debe a que se confunden los dos formatos. Doc y Docx. El caso es que desde 2007 Word (si no me equivoco) introduce el formato Docx(le permite comprimir el documento con más fuerza que Doc y lo protege de manera más confiable). Entonces, si tiene un Word antiguo que no admite este formato, cuando abra un documento en Docx, verá jeroglíficos y nada más. Hay dos soluciones: Además, cuando abre cualquier documento en Word (cuya codificación "duda"), le ofrece la opción de especificarlo usted mismo. En la siguiente imagen se muestra un ejemplo, intente seleccionar:
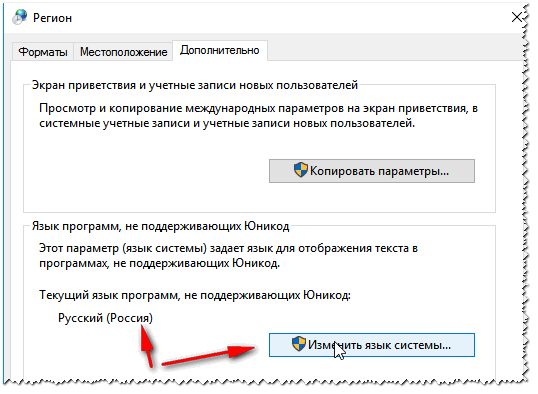
Sucede que alguna ventana o menú de un programa se muestra con jeroglíficos (claro, es imposible leer o entender algo). Regiones e Idiomas en Windows Ubicación - Rusia y en la pestaña "Además" configurar el idioma del sistema "Rusia rusa)" . Después de esto, guarde la configuración y reinicie su PC. Luego verifique nuevamente si la interfaz del programa deseado se muestra normalmente.
Y finalmente, esto probablemente sea obvio para muchos y, sin embargo, algunos abren ciertos archivos en programas que no están diseñados para esto: por ejemplo, en un bloc de notas normal intentan leer un archivo DOCX o PDF. Naturalmente, en este caso, en lugar de texto, verás que los crackers utilizan programas diseñados para ello; de este tipo archivo (WORD 2016+ y Adobe Reader para el ejemplo anterior). Probablemente todos los usuarios de PC se hayan encontrado con un problema similar: abres una página o un documento de Internet Microsoft Word- y en lugar de texto aparecen jeroglíficos (varios “kryakozabry”, letras desconocidas, números, etc. (como en la imagen de la izquierda...)). Es bueno que este documento (con jeroglíficos) no sea particularmente importante para ti, pero ¿y si necesitas leerlo? Muy a menudo me hacen preguntas similares y me piden ayuda para abrir dichos textos. En este breve artículo quiero analizar las razones más populares de la aparición de jeroglíficos (y, por supuesto, eliminarlas). Jeroglíficos en archivos de texto (.txt) El problema más popular. El hecho es que Archivo de texto(generalmente en formato txt, pero también hay formatos: php, css, info, etc.) se pueden guardar en varias codificaciones. Una codificación es un conjunto de caracteres necesarios para garantizar completamente que el texto esté escrito en un alfabeto específico (incluidos números y caracteres especiales). Más detalles sobre esto aquí: https://ru.wikipedia.org/wiki/Character_set La mayoría de las veces sucede una cosa: el documento simplemente se abre con la codificación incorrecta, lo que genera confusión, y en lugar del código de algunos caracteres, se llamarán otros. En la pantalla aparecen varios símbolos extraños (ver Fig. 1)... Arroz. 1. Bloc de notas: problema de codificación Como lidiar con esto? En mi opinión la mejor opción- esto es para instalar un bloc de notas avanzado, por ejemplo Notepad++ o Bred 3. Veamos cada uno de ellos con más detalle. Bloc de notas++ Sitio web oficial: https://notepad-plus-plus.org/ Uno de los mejores blocs de notas tanto para principiantes como para profesionales. Ventajas: programa gratuito, admite el idioma ruso, funciona muy rápido, resalta código, abre todos los formatos de archivos comunes y una gran cantidad de opciones le permite personalizarlo usted mismo. En términos de codificaciones, aquí generalmente hay un orden completo: hay una sección separada "Codificaciones" (ver Fig. 2). Intente cambiar ANSI a UTF-8 (por ejemplo). Después de cambiar la codificación, mi documento de texto se volvió normal y legible: ¡los jeroglíficos desaparecieron (ver Fig. 3)! Sitio web oficial: http://www.astonshell.ru/freeware/bred3/ Otro gran programa diseñado para reemplazar completamente el bloc de notas estándar en Windows. También funciona "fácilmente" con muchas codificaciones, las cambia fácilmente, admite una gran cantidad de formatos de archivo y admite nuevos sistemas operativos Windows (8, 10). Por cierto, Bred 3 es muy útil cuando se trabaja con archivos "antiguos" guardados en formatos MS DOS. Cuando otros programas muestran solo jeroglíficos, Bred 3 los abre fácilmente y le permite trabajar tranquilamente con ellos (ver Fig. 4). Si hay jeroglíficos en lugar de texto en Microsoft Word Lo primero a lo que debes prestar atención es al formato del archivo. El caso es que a partir de Word 2007 nuevo formato- "docx" (anteriormente era solo "doc"). Por lo general, los formatos de archivos nuevos no se pueden abrir en el Word "antiguo", pero a veces sucede que estos archivos "nuevos" se abren en el programa antiguo. Simplemente abra las propiedades del archivo y luego mire la pestaña "Detalles" (como en la Figura 5). De esta manera descubrirá el formato del archivo (en la Fig. 5, el formato del archivo “txt”). Si el formato archivo docx- y tiene un Word antiguo (versión anterior a 2007), simplemente actualice Word a 2007 o superior (2010, 2013, 2016). A continuación, al abrir un archivo, preste atención (por defecto esta opción siempre está activado, a menos, por supuesto, que "no entienda qué ensamblado") - Word le preguntará nuevamente: en qué codificación abrir el archivo (este mensaje aparece ante cualquier "pista" de problemas al abrir el archivo, ver figura 5). Arroz. 6. Word - conversión de archivos La mayoría de las veces, Word determina automáticamente la codificación requerida, pero el texto no siempre es legible. Debe configurar el control deslizante en la codificación deseada cuando el texto sea legible. A veces tienes que adivinar literalmente cómo se guardó un archivo para poder leerlo. Arroz. 7. Word: ¡el archivo es normal (la codificación se eligió correctamente)! Cambiar la codificación en el navegador. Cuando el navegador detecta por error la codificación de una página de Internet, verá exactamente los mismos jeroglíficos (ver Figura 8). Para arreglar la visualización del sitio: cambie la codificación. Esto se hace en la configuración del navegador: Así, en este artículo se analizaron los casos más habituales de aparición de jeroglíficos asociados a una codificación mal definida. Con los métodos anteriores, puede resolver todos los problemas principales relacionados con la codificación incorrecta. Creo que te has encontrado con exploits clasificados como Unicode más de una vez, has buscado la codificación correcta para mostrar una página y has quedado satisfecho con los siguientes trucos aquí y allá. ¡Nunca se sabe qué más! Si quieres saber quién empezó todo este lío y sigue limpiándolo hasta el día de hoy, abróchate los cinturones y sigue leyendo. Como suele decirse, “la iniciativa es punible” y, como siempre, los estadounidenses tienen la culpa de todo. Y fue así. En los albores del apogeo de la industria informática y la expansión de Internet, surgió la necesidad de un sistema universal para representar símbolos. Y en los años 60 del siglo pasado, apareció ASCII: "Código estándar estadounidense para el intercambio de información" (American Código estándar for Information Exchange), una codificación de caracteres familiar de 7 bits. El último octavo bit no utilizado se dejó como bit de control para personalizar la tabla ASCII para satisfacer las necesidades de cada cliente de computadora en una región particular. Este bit permitió ampliar la tabla ASCII para utilizar sus propios caracteres para cada idioma. Se suministraron computadoras a muchos países, donde ya utilizaban su propia tabla modificada. Pero luego esta característica se convirtió en un dolor de cabeza, ya que el intercambio de datos entre computadoras se volvió bastante problemático. Las nuevas páginas de códigos de 8 bits eran incompatibles entre sí: el mismo código podía significar varios caracteres diferentes. Para resolver este problema, ISO (Organización Internacional de Normalización) propuso una nueva tabla, denominada “ISO 8859”. Posteriormente, este estándar pasó a llamarse UCS (“Conjunto de caracteres universales”). Sin embargo, cuando se lanzó UCS por primera vez, ya había aparecido Unicode. Pero como las metas y objetivos de ambas normas coincidían, se decidió unir fuerzas. Bueno, Unicode ha asumido la difícil tarea de darle a cada carácter una designación única. En este momento La última versión de Unicode es 5.2. Quiero advertirles: de hecho, la historia de las codificaciones es muy turbia. Diferentes fuentes proporcionan diferentes datos, por lo que no debes centrarte en una sola cosa, solo ser consciente de cómo se formó todo y seguir los estándares modernos. Espero que no seamos historiadores. Curso intensivo de UnicodeAntes de profundizar en el tema, me gustaría aclarar en qué consiste Unicode. técnicamente. Objetivos este estándar Ya lo sabemos, sólo queda parchear el hardware. Entonces, ¿qué es Unicode? En pocas palabras, esta es una forma de representar cualquier carácter como un código específico para todos los idiomas del mundo. Ultima versión El estándar contiene alrededor de 1.100.000 códigos, que ocupan un espacio desde U+0000 hasta U+10FFFF. ¡Pero ten cuidado aquí! Unicode define estrictamente qué es un código para un carácter y cómo se representará ese código en la memoria. Los códigos de caracteres (por ejemplo, 0041 para el carácter “A”) no tienen ningún significado, pero existe una lógica para representar estos códigos en bytes; esto se hace mediante codificaciones; El Consorcio Unicode ofrece los siguientes tipos de codificaciones, denominadas UTF (Formatos de transformación Unicode). Y aquí están:
El análogo más cercano de UTF-32 es la codificación UCS-4, pero hoy en día se usa con menos frecuencia. A pesar de que UTF-8 y UTF-32 pueden representar un poco más de dos mil millones de caracteres, se decidió limitarnos a un poco más de un millón por razones de compatibilidad con UTF-16. Todo el espacio de código está agrupado en 17 planos, cada uno con 65.536 símbolos. Los símbolos más utilizados se encuentran en el plano base cero. Conocido como BMP - Multiplano básico. En aras de la compatibilidad con versiones anteriores, Unicode tuvo que acomodar caracteres de codificaciones existentes. Pero aquí surge otro problema: hay muchas variantes de caracteres idénticos que deben procesarse de alguna manera. Por lo tanto, se necesita la llamada "normalización", después de la cual ya es posible comparar dos cadenas. Hay 4 formas de normalización:
Ahora hablemos más sobre estas extrañas palabras. Unicode define dos tipos de igualdad de cadenas: canónica y de compatibilidad. El primero implica la descomposición de un símbolo complejo en varias figuras individuales, que en su conjunto forman el símbolo original. La segunda igualdad encuentra el símbolo coincidente más cercano. Y la composición es la combinación de símbolos de diferentes partes, la descomposición es la acción contraria. En general, mira el dibujo, todo encajará. Por razones de seguridad, la normalización se debe realizar antes de enviar la cadena a cualquier filtro para su verificación. Después de esta operación, el tamaño del texto puede cambiar, lo que puede tener consecuencias negativas, pero hablaremos de eso más adelante. En cuanto a teoría, eso es todo, no he dicho mucho todavía, pero espero no haberme perdido nada importante. Unicode es increíblemente vasto, complejo, se publican libros gruesos sobre él y es muy difícil explicar de manera concisa, accesible y completa los conceptos básicos de un estándar tan engorroso. En cualquier caso, para una comprensión más profunda debes consultar los enlaces laterales. Entonces, cuando la imagen con Unicode se haya vuelto más o menos clara, podemos seguir adelante. ilusión visualProbablemente haya oído hablar de la suplantación de IP/ARP/DNS y tenga una buena idea de qué es. Pero también existe la llamada "suplantación de identidad visual": este es el mismo método antiguo que los phishers utilizan activamente para engañar a las víctimas. En tales casos, se utiliza el uso de letras similares, como “o” y “0”, “5” y “s”. Esta es la opción más común, sencilla y más fácil de notar. Un ejemplo es el ataque de phishing a PayPal en el año 2000, que incluso fue mencionado en las páginas de www.unicode.org. Sin embargo, esto tiene poca relevancia para nuestro tema Unicode. Para los más avanzados, Unicode ha aparecido en el horizonte, o más precisamente, IDN, que es una abreviatura de "Nombres de dominio internacionalizados". IDN permite el uso de caracteres del alfabeto nacional en nombres de dominio. Los registradores de nombres de dominio consideran que esto es algo conveniente, dicen, marque Nombre de dominio¡en tu idioma nativo! Sin embargo, esta conveniencia es muy cuestionable. Bueno, está bien, el marketing no es nuestro tema. Pero imagínense el paraíso para los phishers, los especialistas en SEO, los ciberocupas y otros espíritus malignos. Me refiero a un efecto llamado suplantación de IDN. Este ataque pertenece a la categoría de suplantación de identidad visual; en la literatura inglesa también se le llama “ataque homógrafo”, es decir, ataques que utilizan homógrafos (palabras que tienen la misma ortografía). Sí, al escribir letras, nadie se equivocará y no escribirá un dominio deliberadamente falso. Pero la mayoría de las veces los usuarios hacen clic en los enlaces. Si quiere convencerse de la eficacia y sencillez del ataque, mire la imagen. IDNA2003 fue inventado como una especie de panacea, pero ya este año 2010 entró en vigor IDNA2008. Se suponía que el nuevo protocolo resolvería muchos de los problemas del joven IDNA2003, pero introdujo nuevas oportunidades para ataques de suplantación de identidad. Nuevamente surgen problemas de compatibilidad: en algunos casos, la misma dirección en diferentes navegadores puede conducir a diferentes servidores. El punto es que Punycode se puede convertir de diferentes maneras para diferentes navegadores- Todo dependerá de qué especificaciones estándar se admitan. En la figura, como puedes ver, tenemos un archivo llamado evilexe. TXT. ¡Pero esto es falso! En realidad, el archivo se llama eviltxt.exe. ¿Qué clase de basura es esta entre paréntesis, preguntas? Y este es U+202E o ANULACIÓN DE DERECHA A IZQUIERDA, el llamado Bidi (de la palabra bidireccional), un algoritmo Unicode para admitir idiomas como el árabe, el hebreo y otros. Estos últimos tienen escritura de derecha a izquierda. Después de insertar el carácter Unicode RLO, veremos todo lo que viene después del RLO en orden inverso. Como ejemplo este método De la vida real puedo citar un ataque de suplantación de identidad en Mozilla Firfox: cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376. Filtros de derivación - etapa No. 1Hoy en día ya se sabe que las formas largas (no la forma más corta) de UTF-8 no se pueden procesar, ya que se trata de una vulnerabilidad potencial. Sin embargo, esto no puede convencer a los desarrolladores de PHP. Averigüemos qué es este error. Quizás recuerde el filtrado incorrecto y utf8_decode(). Este es el caso que consideraremos con más detalle. Entonces tenemos este código PHP:
|

















Popular:
Nuevo
- Configuración de detalles adicionales e información adicional para la nomenclatura 1c detalles adicionales y diferencias de información
- Qué hacer cuando no hay datos de registro
- Solicitud de selección de datos (fórmulas) en MS EXCEL Selección de Excel por macro de condición
- Correo electrónico temporal temporal de una sola vez Correo electrónico temporal, sitios de correo, registro en redes sociales
- Qué hacer si la computadora no ve el teléfono a través del puerto USB
- ¿Cómo instalar Windows en Mac?
- Firmware de configuración de Asus rt n16
- Cómo averiguar el bitness del sistema operativo y el procesador en Windows
- Cómo desactivar el Firewall de Windows: desactivación completa y deshabilitación de programas individuales Cómo desactivar completamente el firewall de Windows 7
- Potente conversor de archivos HTML a Doc, PDF, Excel, JPEG y texto utilizando el programa Total HTML Converter