Abschnitte der Website
Die Wahl des Herausgebers:
- Überprüfung und Test des Nokia XL Dual SIM-Smartphones. Mobile Kommunikationstechnologien und Datenübertragungsgeschwindigkeiten
- So setzen Sie die Einstellungen bei Samsung zurück
- Machen Sie einen Screenshot auf einem Samsung Galaxy A7-Smartphone
- Gründe für einen Zeitfehler auf einem Laptop und wie man sie behebt. Die Datums- und Uhrzeiteinstellungen auf dem Computer gehen verloren
- Ein iPhone nach dem Kauf einrichten So richten Sie ein iPhone SE nach dem Kauf ein
- Die Tastatur druckt die Buchstaben, die Sie drücken, nicht aus. Die Tastatur funktioniert jedoch nicht
- Sendungsverfolgung durch die Russische Post
- Die besten Möglichkeiten, einen schönen Hintergrund für Ihren YouTube-Kanal zu erstellen
- Samsung-Smartphones auf Werkseinstellungen zurücksetzen
- Was ist Power BI und wie arbeitet man damit?
Werbung
|
Dies war das erste Mal, dass ich so etwas sah – die Dateien und Ordner vom Flash-Laufwerk verschwanden und stattdessen erschienen Dateien mit unverständlichen Namen in Form von „Kryakozyabriks“, nennen wir sie Hieroglyphen. Das Flash-Laufwerk wurde mit Standard geöffnet unter Verwendung von Windows und außerdem gab es leider keine positiven Ergebnisse.
Alle Dateien auf dem Flash-Laufwerk sind verschwunden, bis auf eine. Es erschienen mehrere Dateien mit seltsamen Namen: &, t, n-& usw. Die Dateien auf dem Flash-Laufwerk sind verschwunden, aber Windows zeigt an, dass der freie Speicherplatz belegt ist. Dies deutet darauf hin, dass die für uns interessanten Dateien zwar nicht angezeigt werden, sich aber auf dem Flash-Laufwerk befinden.
Obwohl die Dateien verschwunden sind, ist der Speicherplatz belegt. IN konkreter Fall, 817 MB belegt Der erste Gedanke an die Ursache des Geschehens ist die Wirkung des Virus. Früher, als es einen Virus gab, wurde der Dateimanager FAR-Manager verwendet, der in der Regel alle Dateien (versteckte Dateien und Systemdateien) sieht. Diesmal sah der FAR-Manager jedoch nur das, was der Standard-Windows-Explorer tat ...
Selbst der FAR-Manager konnte die „verlorenen“ Dateien nicht sehen Da Windows fehlende Dateien nicht erkennt, versucht es nicht, Dateiattribute mithilfe von zu ändern Befehlszeile und die Befehle attrib -S -H /S /D.
In dieser Situation habe ich mich versuchsweise für die Verwendung des Betriebssystems entschieden Linux-basiert. In diesem speziellen Fall wurde eine Festplatte mit einem Betriebssystem verwendet Ubuntu-System 10.04.3 (mehr über Ubuntu und wo man es herunterladen kann). Wichtig! Sie müssen Ubuntu nicht auf Ihrem Computer installieren – booten Sie einfach von einer CD, genau wie Sie es mit tun. Nach dem Booten von Ubuntu erscheint der Desktop und Sie können mit Ordnern und Dateien genauso wie in Windows arbeiten.
Wie erwartet sah Ubuntu weitere Dateien im Vergleich zu Windows.
Ubuntu zeigt auch die Dateien an, die unter Windows nicht sichtbar waren (anklickbar) Um sich nicht mit Dateiattributen herumschlagen zu müssen, wurden als nächstes grundlegende Schritte unternommen: Alle angezeigten Dateien wurden ausgewählt und kopiert lokale Festplatte„D“ (natürlich können Sie Dateien dorthin kopieren). Systemfestplatte"C") Jetzt können Sie Windows erneut starten und überprüfen, was passiert ist.
Jetzt sieht Windows mehrere Word-Dateien. Bitte beachten Sie, dass auch Dateinamen korrekt angezeigt werden Leider ist das Problem nicht gelöst, da sich auf dem Flash-Laufwerk deutlich mehr Dateien befanden (gemessen an der Größe von 817 MB), als wir extrahieren konnten. Versuchen wir aus diesem Grund, das Flash-Laufwerk auf Fehler zu überprüfen. Fehlerbehebung bei Flash-LaufwerksfehlernUm Fehler auf Datenträgern zu finden und zu beheben, verfügt Windows über ein Standarddienstprogramm. Schritt 1. Klicken Sie mit der rechten Maustaste auf das Flash-Laufwerkssymbol und wählen Sie den Befehl „Eigenschaften“.
Schritt 2. Gehen Sie zur Registerkarte „Service“ und klicken Sie auf die Schaltfläche „Prüfung ausführen“.
Schritt 3. Klicken Sie auf die Schaltfläche „Starten“.
Nach Überprüfung und Reparatur Systemfehler, erscheint eine entsprechende Meldung.
Meldung: „Einige Fehler wurden gefunden und behoben“ Nach der Beseitigung der Fehler verschwanden die Dateien mit Hieroglyphen und erschienen im Stammverzeichnis des Flash-Laufwerks versteckter Ordner mit dem Namen FOUND.000.
Im Ordner FOUND.000 befanden sich 264 Dateien mit der Erweiterung CHK. Dateien mit der Erweiterung CHK können Dateifragmente speichern verschiedene Arten, extrahiert aus Festplatte und Flash-Laufwerke mit den Dienstprogrammen ScanDisk oder CHKDISK. Wenn beispielsweise alle Dateien auf dem Flash-Laufwerk vom gleichen Typ wären, Word-Dokumente mit der docx-Erweiterung, dann in Dateimanager Totaler Kommandant Wählen Sie alle Dateien aus und drücken Sie die Tastenkombination Strg + M (Dateien – Gruppenumbenennung). Wir geben an, nach welcher Erweiterung Sie suchen und in was Sie sie ändern müssen.
In diesem speziellen Fall wusste ich nur, dass sich auf dem Flash-Laufwerk Word-Dokumente und Dateien mit Power-Point-Präsentationen befanden. Das zufällige Ändern von Erweiterungen ist sehr problematisch, daher ist es besser, sie zu verwenden Spezialprogramme— Sie bestimmen selbst, welche Art von Daten in der Datei gespeichert werden. Ein solches Programm ist kostenloses Dienstprogramm, die keine Installation auf Ihrem Computer erfordert. Geben Sie den Quellordner an (ich habe die CHK-Dateien dort abgelegt). Festplatte). Als nächstes habe ich die Option gewählt, dass Dateien mit unterschiedlichen Erweiterungen in unterschiedlichen Ordnern abgelegt werden.
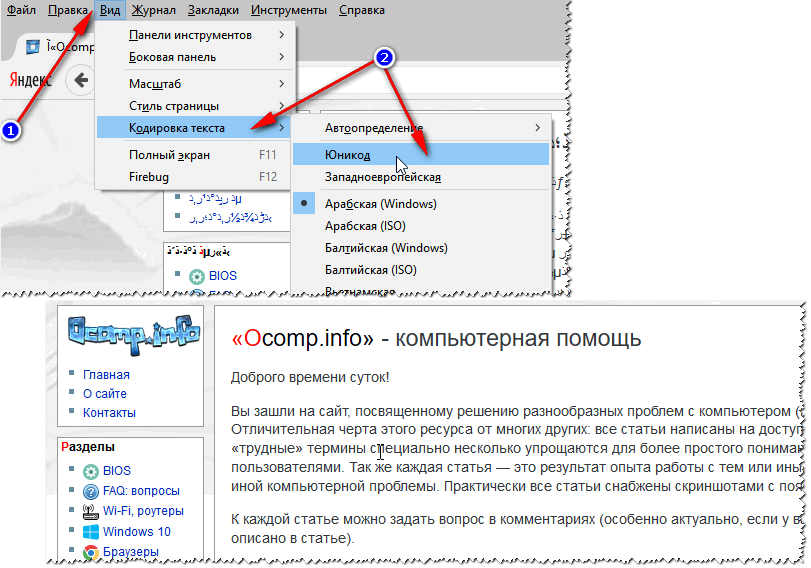
Alles, was Sie tun müssen, ist auf „Start“ zu klicken. Als Ergebnis des Dienstprogramms erschienen drei Ordner: Der Inhalt von acht Akten blieb unerkannt. Die Hauptaufgabe wurde jedoch abgeschlossen, Word-Dokumente und Fotos wurden wiederhergestellt. Der Nachteil besteht darin, dass es nicht möglich war, ähnliche Dateinamen wiederherzustellen, sodass Sie natürlich mit der Umbenennung von Word-Dokumenten experimentieren müssen. Bei Dateien mit Bildern funktionieren auch Namen wie FILE0001.jpg, FILE0002.jpg usw. Benutzerfrage Guten Tag. Bitte sagen Sie mir, warum auf einigen Seiten in meinem Browser Hieroglyphen, Quadrate und wer weiß was (nichts ist lesbar) anstelle von Text angezeigt werden. Das ist vorher nicht passiert. Vielen Dank im Voraus... Guten Tag! Tatsächlich werden manchmal beim Öffnen einer Internetseite anstelle von Text verschiedene „Kryakozabry“ (wie ich sie nenne) angezeigt, und es ist unmöglich, sie zu lesen. Dies liegt daran, dass der Text auf der Seite in einer Kodierung geschrieben ist (mehr dazu erfahren Sie hier) und der Browser versucht, ihn in einer anderen zu öffnen. Aufgrund dieser Diskrepanz gibt es statt Text einen unverständlichen Zeichensatz. Versuchen wir, das Problem zu beheben ... BrowserEigentlich schon vorher Internet Explorer haben oft ähnliche Cracks ausgegeben, 👉 (Chrome, Yandex-Browser, Opera, Firefox) - sie bestimmen die Kodierung recht gut und machen sehr selten Fehler. 👌 Ich sage noch mehr: In einigen Versionen des Browsers wurde die Auswahl der Kodierung bereits entfernt. Um diesen Parameter „manuell“ zu konfigurieren, müssen Sie Add-Ons herunterladen oder für 10 Ticks in den Dschungel der Einstellungen gehen. . Angenommen, der Browser hat die Kodierung falsch erkannt und Sie sehen Folgendes (wie im Screenshot unten 👇).
👉 Übrigens! Am häufigsten kommt es zu Verwechslungen zwischen den Kodierungen UTF (Unicode) und Windows-1251 (die meisten russischsprachigen Websites werden in diesen Kodierungen erstellt).
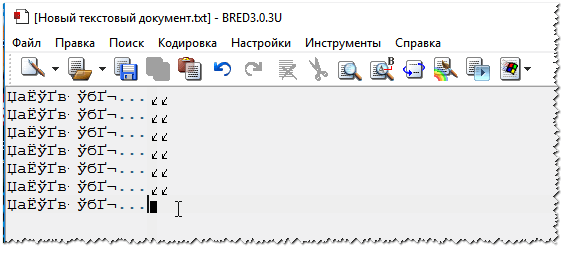
Noch ein Tipp: Wenn Sie nicht finden, wie Sie die Codierung in Ihrem Browser ändern können (und es im Allgemeinen unrealistisch ist, Anweisungen für jeden Browser zu geben!), empfehle ich, zu versuchen, die Seite in einem anderen Browser zu öffnen. Sehr oft öffnet ein anderes Programm die Seite so, wie sie sollte. TextdokumenteBeim Öffnen einiger Textdokumente werden viele Fragen zu Crackern gestellt. Besonders alte, zum Beispiel beim Lesen der Readme-Datei in einem Programm des letzten Jahrhunderts (z. B. für Spiele). Natürlich können viele moderne Notizblöcke die früher verwendete DOS-Kodierung einfach nicht lesen. Um dieses Problem zu lösen, empfehle ich die Verwendung des Bread 3-Editors. Gezüchtet 3 Ein einfacher und praktischer Textnotizblock. Eine unersetzliche Sache, wenn Sie mit alten Textdateien arbeiten müssen. Mit Bred 3 können Sie die Kodierung mit einem Klick ändern und unlesbaren Text lesbar machen! Neben Textdateien unterstützt es eine ziemlich große Vielfalt an Dokumenten. Im Allgemeinen empfehle ich es! ✌ Versuchen Sie, Ihres in Bred 3 zu öffnen Text dokument(womit es Probleme gibt). Ein Beispiel ist in meinem Screenshot unten dargestellt.
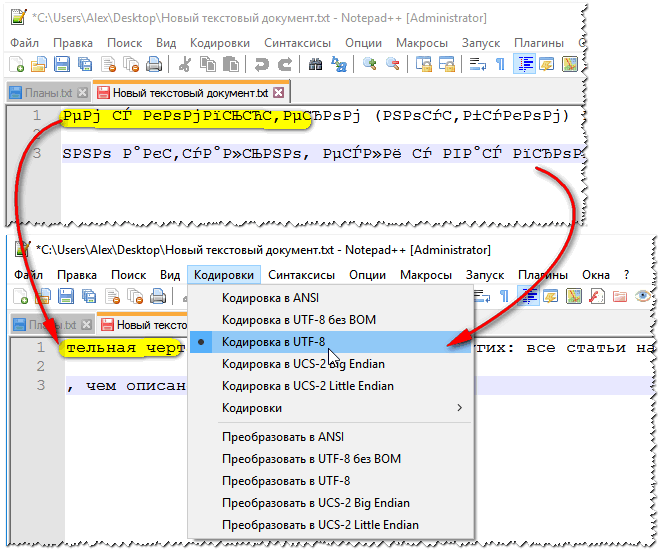
Ein anderer Notizblock – Notepad++ – eignet sich auch zum Arbeiten mit Textdateien verschiedener Kodierungen. Im Allgemeinen eignet es sich natürlich besser zum Programmieren, weil ... Unterstützt verschiedene Hintergrundbeleuchtungen zum einfacheren Lesen des Codes. Ein Beispiel für die Änderung der Kodierung ist unten dargestellt: Um den Text zu lesen, reichte es im folgenden Beispiel aus, die ANSI-Kodierung auf UTF-8 zu ändern.
Sehr oft liegt das Problem mit Rissen in Word daran, dass die beiden Formate verwechselt werden Doc und Docx. Tatsache ist, dass Word (wenn ich mich nicht irre) das Format seit 2007 eingeführt hat Docx(Ermöglicht eine stärkere Komprimierung des Dokuments als bei Doc und schützt es zuverlässiger). Wenn Sie also ein altes Word-Dokument haben, das dieses Format nicht unterstützt, sehen Sie beim Öffnen eines Dokuments in Docx nur Hieroglyphen und nichts weiter. Es gibt zwei Lösungen: Wenn Sie ein Dokument in Word öffnen (an dessen Codierung er „zweifelt“), bietet er Ihnen außerdem die Möglichkeit, es selbst anzugeben. Ein Beispiel ist im Bild unten dargestellt. Versuchen Sie es mit der Auswahl:
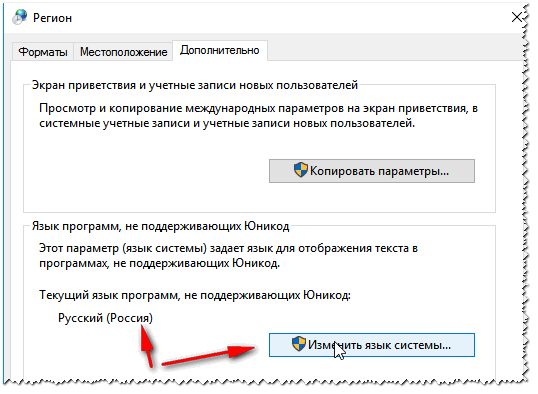
Es kommt vor, dass ein Fenster oder Menü in einem Programm mit Hieroglyphen angezeigt wird (es ist natürlich unmöglich, etwas zu lesen oder zu verstehen). Regionen und Sprachen in Windows Standort – Russland Und in der Registerkarte "Zusätzlich" Legen Sie die Systemsprache fest „Russisches Russland)“ . Speichern Sie anschließend die Einstellungen und starten Sie Ihren PC neu. Überprüfen Sie anschließend noch einmal, ob die Oberfläche des gewünschten Programms normal angezeigt wird.
Und schließlich ist dies wahrscheinlich für viele offensichtlich, und dennoch öffnen einige bestimmte Dateien in Programmen, die nicht dafür vorgesehen sind: Beispielsweise versuchen sie in einem normalen Notizblock, eine DOCX- oder PDF-Datei zu lesen. Natürlich sehen Sie sich in diesem Fall anstelle von Text die Cracker an; verwenden Sie die dafür vorgesehenen Programme dieser Art Datei (WORD 2016+ und Adobe Reader für das obige Beispiel). Wahrscheinlich kennt jeder PC-Nutzer ein ähnliches Problem: Man öffnet eine Internetseite oder ein Dokument Microsoft Word- und anstelle von Text sehen Sie Hieroglyphen (verschiedene „kryakozabry“, unbekannte Buchstaben, Zahlen usw. (wie im Bild links...)). Es ist gut, wenn dieses Dokument (mit Hieroglyphen) für Sie nicht besonders wichtig ist, aber was ist, wenn Sie es lesen müssen?! Sehr oft werden mir ähnliche Fragen und Bitten um Hilfe beim Öffnen solcher Texte gestellt. In diesem kurzen Artikel möchte ich die häufigsten Gründe für das Auftreten von Hieroglyphen untersuchen (und sie natürlich beseitigen). Hieroglyphen in Textdateien (.txt) Das beliebteste Problem. Die Sache ist die Textdatei(normalerweise im TXT-Format, es gibt aber auch Formate: PHP, CSS, Info usw.) können in verschiedenen Kodierungen gespeichert werden. Eine Kodierung ist ein Satz von Zeichen, die erforderlich sind, um vollständig sicherzustellen, dass Text in einem bestimmten Alphabet geschrieben wird (einschließlich Zahlen und Sonderzeichen). Weitere Details dazu hier: https://ru.wikipedia.org/wiki/Character_set Am häufigsten passiert eines: Das Dokument wird einfach in der falschen Kodierung geöffnet, was zu Verwirrung führt, und anstelle des Codes einiger Zeichen werden andere aufgerufen. Auf dem Bildschirm erscheinen verschiedene seltsame Symbole (siehe Abb. 1)... Reis. 1. Notepad – Kodierungsproblem Wie gehe ich damit um? Meiner Meinung nach Die beste Option- Hiermit wird ein erweiterter Notizblock installiert, zum Beispiel Notepad++ oder Bred 3. Schauen wir uns jeden einzelnen davon genauer an. Notepad++ Offizielle Website: https://notepad-plus-plus.org/ Einer der besten Notizblöcke für Anfänger und Profis. Vorteile: kostenloses Programm, unterstützt die russische Sprache, arbeitet sehr schnell, Code-Hervorhebung, Öffnen aller gängigen Dateiformate, eine Vielzahl von Optionen ermöglichen es Ihnen, es selbst anzupassen. Bezüglich der Kodierungen herrscht hier grundsätzlich vollständige Ordnung: Es gibt einen eigenen Abschnitt „Kodierungen“ (siehe Abb. 2). Versuchen Sie einfach, ANSI in UTF-8 zu ändern (zum Beispiel). Nach der Änderung der Kodierung wurde mein Textdokument normal und lesbar – die Hieroglyphen verschwanden (siehe Abb. 3)! Offizielle Website: http://www.astonshell.ru/freeware/bred3/ Ein weiteres großartiges Programm, das den Standard-Notizblock in Windows vollständig ersetzen soll. Es funktioniert auch „einfach“ mit vielen Kodierungen, ändert diese problemlos, unterstützt eine große Anzahl von Dateiformaten und unterstützt neue Windows-Betriebssysteme (8, 10). Übrigens ist Bred 3 sehr hilfreich, wenn Sie mit „alten“ Dateien arbeiten, die in MS-DOS-Formaten gespeichert sind. Wenn andere Programme nur Hieroglyphen anzeigen, öffnet Bred 3 diese problemlos und ermöglicht Ihnen ein ruhiges Arbeiten damit (siehe Abb. 4). Wenn in Microsoft Word Hieroglyphen anstelle von Text vorhanden sind Das allererste, worauf Sie achten müssen, ist das Dateiformat. Tatsache ist, dass ab Word 2007 neues Format- „docx“ (vorher war es nur „doc“). Normalerweise können neue Dateiformate nicht im „alten“ Word geöffnet werden, es kommt jedoch manchmal vor, dass diese „neuen“ Dateien im alten Programm geöffnet werden. Öffnen Sie einfach die Dateieigenschaften und sehen Sie sich dann die Registerkarte „Details“ an (wie in Abbildung 5). Auf diese Weise erfahren Sie das Dateiformat (in Abb. 5 das „txt“-Dateiformat). Wenn das Format docx-Datei- und Sie haben ein altes Word (unter Version 2007) - dann aktualisieren Sie Word einfach auf 2007 oder höher (2010, 2013, 2016). Achten Sie als Nächstes beim Öffnen einer Datei darauf (standardmäßig). diese Option ist immer aktiviert, es sei denn natürlich, Sie haben „Ich verstehe nicht, welche Assembly“) – Word fragt Sie erneut: In welcher Codierung soll die Datei geöffnet werden (diese Meldung erscheint bei jedem „Hinweis“ auf Probleme beim Öffnen der Datei, siehe Abb. 5). Reis. 6. Word-Dateikonvertierung Meistens ermittelt Word automatisch die erforderliche Kodierung, der Text ist jedoch nicht immer lesbar. Sie müssen den Schieberegler auf die gewünschte Kodierung einstellen, wenn der Text lesbar wird. Manchmal muss man buchstäblich raten, wie die Datei gespeichert wurde, um sie lesen zu können. Reis. 7. Word - die Datei ist normal (die Kodierung ist richtig gewählt)! Ändern der Kodierung im Browser Wenn der Browser fälschlicherweise die Kodierung einer Internetseite erkennt, sehen Sie genau die gleichen Hieroglyphen (siehe Abbildung 8). Um die Anzeige der Site zu korrigieren: Ändern Sie die Kodierung. Dies erfolgt in den Browsereinstellungen: Daher wurden in diesem Artikel die häufigsten Fälle des Auftretens von Hieroglyphen analysiert, die mit einer falsch definierten Kodierung verbunden sind. Mit den oben genannten Methoden können Sie alle Hauptprobleme mit falscher Kodierung lösen. Ich denke, Sie sind mehr als einmal auf Exploits gestoßen, die als Unicode klassifiziert sind, haben nach der richtigen Kodierung für die Anzeige einer Seite gesucht und sind hier und da mit den nächsten Gimmicks zufrieden gewesen. Man weiß nie, was noch! Wenn Sie herausfinden möchten, wer dieses ganze Durcheinander verursacht hat und es bis heute aufräumt, schnallen Sie sich an und lesen Sie weiter. Wie sie sagen: „Initiative ist strafbar“ und wie immer sind die Amerikaner an allem schuld. Und es war so. Zu Beginn der Blütezeit der Computerindustrie und der Verbreitung des Internets entstand der Bedarf an einem universellen System zur Darstellung von Symbolen. Und in den 60er Jahren des letzten Jahrhunderts erschien ASCII – „American Standard Code for Information Interchange“ (amerikanisch). Standardcode für Informationsaustausch), eine bekannte 7-Bit-Zeichenkodierung. Das letzte achte ungenutzte Bit wurde als Steuerbit belassen, um die ASCII-Tabelle an die Bedürfnisse jedes Computerkunden in einer bestimmten Region anzupassen. Dieses Bit ermöglichte es, die ASCII-Tabelle zu erweitern, um für jede Sprache eigene Zeichen zu verwenden. Computer wurden in viele Länder geliefert, wo bereits eine eigene modifizierte Tabelle verwendet wurde. Doch später wurde diese Funktion zu einem Problem, da der Datenaustausch zwischen Computern ziemlich problematisch wurde. Die neuen 8-Bit-Codepages waren untereinander nicht kompatibel – der gleiche Code konnte mehrere verschiedene Zeichen bedeuten. Um dieses Problem zu lösen, hat die ISO (International Organization for Standardization) eine neue Tabelle vorgeschlagen, nämlich „ISO 8859“. Dieser Standard wurde später in UCS („Universal Character Set“) umbenannt. Als UCS jedoch erstmals veröffentlicht wurde, war Unicode bereits erschienen. Da aber die Ziele beider Standards übereinstimmten, entschloss man sich, die Kräfte zu bündeln. Nun, Unicode hat sich der schwierigen Aufgabe gestellt, jedem Zeichen eine eindeutige Bezeichnung zu geben. An dieser Moment Die neueste Version von Unicode ist 5.2. Ich möchte Sie warnen – tatsächlich ist die Geschichte mit den Kodierungen sehr unklar. Unterschiedliche Quellen liefern unterschiedliche Fakten. Sie sollten sich also nicht auf eine Sache konzentrieren, sondern sich darüber im Klaren sein, wie alles entstanden ist, und modernen Standards folgen. Ich hoffe, wir sind keine Historiker. Unicode-CrashkursBevor ich mich mit dem Thema befasse, möchte ich klären, worum es bei Unicode geht technisch. Ziele dieser Norm Wir wissen bereits, dass nur noch die Hardware repariert werden muss. Was ist Unicode? Einfach ausgedrückt ist dies eine Möglichkeit, jedes Zeichen als spezifischen Code für alle Sprachen der Welt darzustellen. Letzte Version Der Standard enthält etwa 1.100.000 Codes, die den Platz von U+0000 bis U+10FFFF einnehmen. Aber Vorsicht hier! Unicode definiert streng, was ein Code für ein Zeichen ist und wie dieser Code im Speicher dargestellt wird. Zeichencodes (z. B. 0041 für das Zeichen „A“) haben keine Bedeutung, es gibt jedoch eine Logik zur Darstellung dieser Codes in Bytes; dies geschieht durch Kodierungen. Das Unicode-Konsortium bietet die folgenden Arten von Kodierungen an, die als UTF (Unicode Transformation Formats) bezeichnet werden. Und hier sind sie:
Das nächste Analogon von UTF-32 ist die UCS-4-Kodierung, wird heute jedoch seltener verwendet. Obwohl UTF-8 und UTF-32 etwas mehr als zwei Milliarden Zeichen darstellen können, wurde beschlossen, uns aus Gründen der Kompatibilität mit UTF-16 auf etwas mehr als eine Million zu beschränken. Der gesamte Coderaum ist in 17 Ebenen mit jeweils 65.536 Symbolen gruppiert. Die am häufigsten verwendeten Symbole befinden sich in der Null-Basisebene. Wird als BMP – Basic MultiPlane bezeichnet. Aus Gründen der Abwärtskompatibilität musste Unicode Zeichen aus vorhandenen Kodierungen berücksichtigen. Doch hier entsteht ein weiteres Problem – es gibt viele Varianten identischer Zeichen, die irgendwie verarbeitet werden müssen. Daher ist eine sogenannte „Normalisierung“ erforderlich, nach der bereits ein Vergleich zweier Zeichenfolgen möglich ist. Es gibt 4 Formen der Normalisierung:
Lassen Sie uns nun mehr über diese seltsamen Worte sprechen. Unicode definiert zwei Arten der String-Gleichheit – kanonisch und Kompatibilität. Bei der ersten handelt es sich um die Zerlegung eines komplexen Symbols in mehrere Einzelfiguren, die als Ganzes das ursprüngliche Symbol bilden. Die zweite Gleichung findet das am besten passende Symbol. Und Komposition ist die Kombination von Symbolen aus verschiedenen Teilen, Zerlegung ist der gegenteilige Vorgang. Schauen Sie sich im Allgemeinen die Zeichnung an, alles wird zusammenpassen. Aus Sicherheitsgründen sollte die Normalisierung durchgeführt werden, bevor die Zeichenfolge zur Überprüfung an Filter gesendet wird. Nach diesem Vorgang kann sich die Textgröße ändern, was negative Folgen haben kann, aber dazu später mehr. Theoretisch ist das alles, ich habe noch nicht viel gesagt, aber ich hoffe, ich habe nichts Wichtiges übersehen. Unicode ist unglaublich umfangreich, komplex, es werden dicke Bücher darüber veröffentlicht und es ist sehr schwierig, die Grundlagen eines solch umständlichen Standards prägnant, verständlich und vollständig zu erklären. Für ein tieferes Verständnis sollten Sie sich auf jeden Fall die Seitenlinks ansehen. Wenn das Bild mit Unicode also mehr oder weniger klar geworden ist, können wir weitermachen. Visuelle IllusionSie haben wahrscheinlich schon von IP/ARP/DNS-Spoofing gehört und haben eine gute Vorstellung davon, was es ist. Es gibt aber auch das sogenannte „visuelle Spoofing“ – das ist die gleiche alte Methode, die Phisher aktiv nutzen, um Opfer zu täuschen. In solchen Fällen werden ähnliche Buchstaben wie „o“ und „0“, „5“ und „s“ verwendet. Dies ist die gebräuchlichste und einfachste Option und leichter zu erkennen. Ein Beispiel ist der Phishing-Angriff auf PayPal im Jahr 2000, der sogar auf den Seiten von www.unicode.org erwähnt wurde. Für unser Unicode-Thema hat dies jedoch wenig Relevanz. Für Fortgeschrittene ist Unicode am Horizont aufgetaucht, genauer gesagt IDN, eine Abkürzung für „Internationalized Domain Names“. IDN erlaubt die Verwendung nationaler Alphabetzeichen in Domainnamen. Domainnamen-Registrare positionieren dies als eine bequeme Sache, sagen sie: Wählen Domainname in deiner Muttersprache! Allerdings ist dieser Komfort sehr fraglich. Na gut, Marketing ist nicht unser Thema. Aber stellen Sie sich vor, was für ein Zufluchtsort dies für Phisher, SEO-Spezialisten, Cybersquatter und andere böse Geister ist. Ich spreche von einem Effekt namens IDN-Spoofing. Dieser Angriff gehört zur Kategorie des visuellen Spoofings; in der englischen Literatur wird er auch als „Homograph-Angriff“ bezeichnet, also Angriffe mit Homographen (Wörtern mit identischer Schreibweise). Ja, beim Tippen von Buchstaben macht niemand einen Fehler und gibt keine absichtlich falsche Domain ein. Am häufigsten klicken Benutzer jedoch auf Links. Wenn Sie sich von der Wirksamkeit und Einfachheit des Angriffs überzeugen möchten, schauen Sie sich das Bild an. IDNA2003 wurde als eine Art Allheilmittel erfunden, doch bereits in diesem Jahr, 2010, trat IDNA2008 in Kraft. Das neue Protokoll sollte viele Probleme des jungen IDNA2003 lösen, eröffnete jedoch neue Möglichkeiten für Spoofing-Angriffe. Es treten erneut Kompatibilitätsprobleme auf – in manchen Fällen kann die gleiche Adresse in verschiedenen Browsern zu unterschiedlichen Servern führen. Der Punkt ist, dass Punycode auf verschiedene Arten konvertiert werden kann verschiedene Browser- Alles hängt davon ab, welche Standardspezifikationen unterstützt werden. Wie Sie in der Abbildung sehen können, haben wir eine Datei namens evilexe. txt. Aber das ist falsch! Die Datei heißt eigentlich eviltxt.exe. Was für ein Mist ist das in Klammern, fragen Sie? Und das ist U+202E oder RIGHT-TO-LEFT OVERRIDE, das sogenannte Bidi (vom Wort bidirektional) – ein Unicode-Algorithmus zur Unterstützung von Sprachen wie Arabisch, Hebräisch und anderen. Letztere haben eine Schrift von rechts nach links. Nach dem Einfügen des Unicode-Zeichens RLO sehen wir alles, was nach dem RLO kommt, in umgekehrter Reihenfolge. Als Beispiel diese Methode Aus dem wirklichen Leben kann ich einen Spoofing-Angriff in Mozilla Firfox zitieren – cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2009-3376. Filter umgehen – Stufe Nr. 1Heute ist bereits bekannt, dass lange Formen (nicht kürzeste Form) von UTF-8 nicht verarbeitet werden können, da dies eine potenzielle Schwachstelle darstellt. Allerdings lassen sich PHP-Entwickler davon nicht überzeugen. Lassen Sie uns herausfinden, was dieser Fehler ist. Vielleicht erinnern Sie sich an falsche Filterung und utf8_decode(). Dies ist der Fall, den wir genauer betrachten werden. Wir haben also diesen PHP-Code:
|

















| Lesen: |
|---|
Beliebt:

Neu
- So setzen Sie die Einstellungen bei Samsung zurück
- Machen Sie einen Screenshot auf einem Samsung Galaxy A7-Smartphone
- Gründe für einen Zeitfehler auf einem Laptop und wie man sie behebt. Die Datums- und Uhrzeiteinstellungen auf dem Computer gehen verloren
- Ein iPhone nach dem Kauf einrichten So richten Sie ein iPhone SE nach dem Kauf ein
- Die Tastatur druckt die Buchstaben, die Sie drücken, nicht aus. Die Tastatur funktioniert jedoch nicht
- Sendungsverfolgung durch die Russische Post
- Die besten Möglichkeiten, einen schönen Hintergrund für Ihren YouTube-Kanal zu erstellen
- Samsung-Smartphones auf Werkseinstellungen zurücksetzen
- Was ist Power BI und wie arbeitet man damit?
- Netzwerkadapter – was ist das?